망나니 개발자님은 17년에 3학년인거 보니...어쩌면 94년생 동갑이신거 같은데,
인생 선배도 이런 선배가 없다...진짜 깔끔한 정리, 아주깔끔한 이미지 들...
과연 이런 글들을 작성하시는데 얼마나 걸리셨을까 싶다....
다시한번...망나니 개발자님께 감사드리며.....
1. 데이터 베이스 시스템
1. 데이터베이스와 데이터베이스 시스템
[ 데이터, 정보, 지식 ]
-
데이터 : 관찰의 결과로 나타난 정량적 혹은 정성적인 실제 값
-
정보 : 데이터에 의미를 부여한 것
-
지식 : 사물이나 현상에 대한 이해
아래와 같은 그림에서 에베레스트가 8848m라는 것은 데이터가 되며, 에베레스트가 세계에서 가장 높은 산이라는 것은 데이터에 의미를 부여한 정보가 되고, 에베레스트에 관한 보고서는 지식이 됩니다.

[ 일상생활의 데이터베이스]
-
데이터베이스 : 조직에 필요한 정보를 얻기 위해 논리적으로 연관된 데이터를 모아 구조적으로 통합해 놓은 것
-
데이터베이스 시스템은 데이터의 검색(select)과 변경(insert, delete 등) 작업을 주로 수행함
-
변경이란 시간에 따라 변하는 데이터 값을 데이터베이스에 반영하기 위해 수행하는 삽입, 삭제, 수정 등의 작업을 말함.
간단히 말해서 데이터베이스는 우리에게 필요한 정보들을 구조적으로 모아둔 것이라고 이해하면 됩니다.
일상생활에서 사용되는 데이터베이스로는 아래와 같은 것들이 있습니다.

[ 데이터베이스의 개념]
-
통합된 데이터: 데이터를 통합하는 개념. 각자 사용하던 데이터의 중복을 최소화하여 중복으로 인한 데이터 불일치 제거
-
저장된 데이터: 문서로 보관된 데이터가 아니라 컴퓨터 저장장치에 저장된 데이터
-
운영 데이터: 조직의 목적을 위해 사용되는 데이터. 즉, 업무를 위한 검색을 목적으로 저장됨
-
공용 데이터: 한 사람 또는 한 업무를 위해 사용되는 데이터가 아니라 공동으로 사용되는 데이터를 의미
A와 B에서 사과의 가격이라는 데이터가 다를 경우에 이를 하나로 통합하여 합치는 것을 통합된 데이터라고 합니다. 기존에는 문서로 보관한 데이터를 컴퓨터에 저장한다는 개념을 저장된 데이터, 조직을 운영하기 위해서 만든 데이터를 운영 데이터, 모두를 위한 데이터라는 의미의 공용 데이터라는 총 4가지의 개념이 있습니다. 아래의 그림에서 예시를 들며 설명해보도록 하겠습니다.

위 그림에서는 컴퓨터 저장장치에 저장된 학사 데이터, 등록 데이터, 수강데이터를 통합하였으며,
학교의 관리자들이 학교의 운영을 용이하게 하기 위해서 구축하였습니다.
[ 데이터베이스의 특징]
-
실시간 접근성: 데이터베이스는 실시간으로 서비스된다. 사용자가 데이터를 요청하면 수 초 내에 결과를 서비스한다.
-
계속적인 변화: 데이터베이스에 저장된 내용은 한 순간의 상태이지만, 데이터 값은 시간에 따라 항상 바뀐다.
-
동시 공유: 데이터베이스는 서로 다른 업무, 여러 사용자에게 동시에 공유된다.(병행= parallel)
-
내용에 따른 참조: 데이터베이스에 저장된 데이터는 물리적인 위치가 아니라 값에 따라 참조된다.
예를 들어, 우리가 어떤 프로그램에 로그인을 한다고 할 때, 아이디와 비밀번호를 입력한 후 로그인 요청을 보내면 실시간으로 서버로부터 응답을 받을 수 있습니다. 로그인을 하여 어떤 물건을 구매하려고 하는 경우에, 그 물건의 구매 가격은 계속해서 변화하며 그 물건에는 동시에 여러 사람이 구매를 위해 접근할 수 있습니다. 또한, 우리는 어떤 데이터가 메모리의 어느 주소에 저장되어있는지 몰라도 '사과'라는 내용을 검색하면 우리가 원하는 값을 찾을 수 있고 이를 '내용에 따른 참조' 라고 합니다.
[ 데이터베이스 시스템의 구성]
-
DBMS: 사용자와 데이터베이스를 연결시켜주는 소프트웨어
-
데이터베이스: 데이터를 모아둔 토대
-
데이터 모델: 데이터가 저장되는 기법에 관한 내용
뒤에서 자세히 다루겠지만 이해를 위해 간단히만 설명하자면, 일반적으로 데이터들은 데이터베이스에 저장이 되어있습니다. 그런데 그러한 데이터를 어떻게 저장할 것인지를 의미하는 것이 데이터 모델이고, 개발자가 데이터베이스로부터 데이터를 꺼내오기 위해서 데이터베이스와 연결을 시켜주는 소프트웨어가 DBMS(DataBaseManagementSystem)입니다.

2. 데이터베이스 시스템의 발전
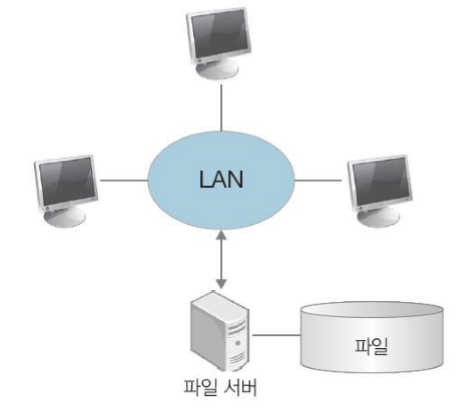
[ 1. 파일 시스템 ]
-
데이터를 파일단위로 파일서버에 저장
-
각 컴퓨터는 LAN을 통하여 파일 서버에 연결되어 있고, 파일 서버에 저장된 데이터를 사용하기 위해서 각 컴퓨터의 으용 프로그램에서 열기/닫기(Open/Close)를 요청
-
각 응용프로그램이 독립적으로 파일을 다루기 때문에 데이터가 중복 저장될 가능성이 있음
-
동시에 파일을 다루기 때문에 데이터의 일관성이 훼손될 수 있음
파일 시스템은 서버에 하나의 파일을 두고 여러개의 클라이언트가 그 파일에 접근하는 방식입니다. 하지만 이러한 파일 시스템은 데이터의 중복 저장과 일관성 훼손이라는 치명적인 단점을 갖게 됩니다. A, B, C 세개의 클라이언트가 도서에 관한 파일서버의 파일에 데이터를 추가한다고 합시다. A, B, C가 모두 '데이터베이스 개론'이라는 책을 추가하기를 원한다고 할 때 A, B, C가 각각 책에 대한 정보를 파일에 추가하여 동일한 정보가 중복되어 저장될 위험이 있습니다. 또한 A에서 '데이터베이스 개론'이라는 원가 10000원의 책에 대해 가격을 2000올려서 12000으로 저장했다고 합시다. 그런데 이미 10000원이라는 가격으로 책에 대한 정보를 얻은 B가 1000원을 올려서 저장을 또 했다고 합시다. 이러한 상황에서 파일 시스템에는 A가 저장한 12000원의 데이터가 사라지고 데이터의 일관성이 훼손되게 됩니다.
파일 시스템의 구조를 그림으로 나타내면 아래와 같습니다.
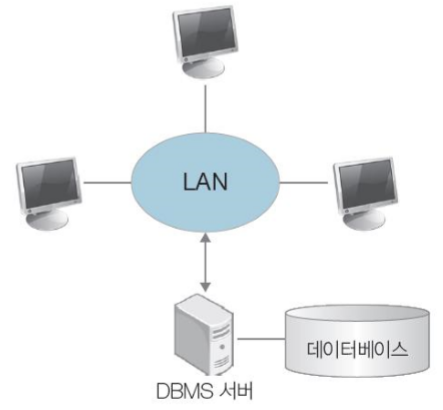
[ 2. 데이터베이스 시스템 ]
-
DBMS를 도입하여 데이터를 통합 관리하는 시스템
-
DBMS가 설치되어 데이터를 가진 쪽을 서버(Server), 데이터를 요청하는 쪽을 클라이언트(Client)라고 함
-
DBMS서버가 파일을 다루며 데이터의 일관성 유지, 복구, 동시 접근 제어 등의 기능 수행
-
데이터의 중복을 줄이고 데이터를 표준화하며 무결성을 유지함
클라이언트는 데이터베이스에 있는 데이터를 얻기 위해 서버로 요청을 하는데, 이때 데이터베이스로의 연결을 위해 사용되는 것이 DBMS서버입니다. 언뜻 보면 파일 시스템과 비슷해 보일 수 있지만, DBMS서버는 데이터의 일관성 유지, 복구, 동시 접근 제어 등의 기능을 수행한다는 점에서 상당히 큰 차이를 가집니다.
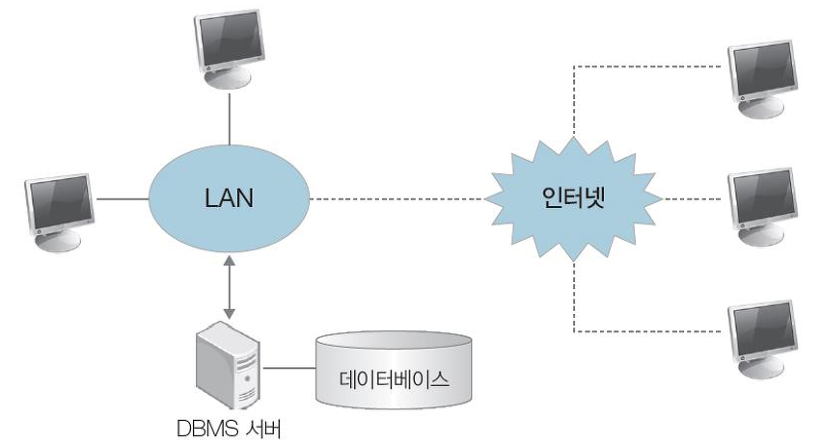
[ 3. 웹 데이터베이스 시스템 ]
-
데이터베이스를 웹 브라우저에서 사용할 수 있도록 서비스하는 시스템
-
불특정 다수의 고객을 상대로 하는 온라인 상거래나 공공 민원 서비스 등에 사용됨
기존의 데이터베이스 시스템은 LAN으로 연결된 컴퓨터만 접근가능했다면, 웹 데이터베이스 시스템은 인터넷을 통해서 LAN으로 연결되어있지 않은 클라이언트들도 데이터베이스로 접근가능하다는 장점을 갖게 되었습다.

[ 4. 분산 데이터베이스 시스템 ]
-
여러 곳에 분산된 DBMS 서버를 연결하여 운영하는 시스템
-
대규모의 응용 시스템에 사용됨
클라이언트의 수가 많아지면서 하나의 서버가 이 모든 것을 감당하기에는 버거운 수준까지 이르렀습니다. 이러한 경우에 여러 개의 서버로 분리하여 서버끼리의 동기화를 유지하며 운영하는 것이 분산 데이터베이스 시스템입니다.
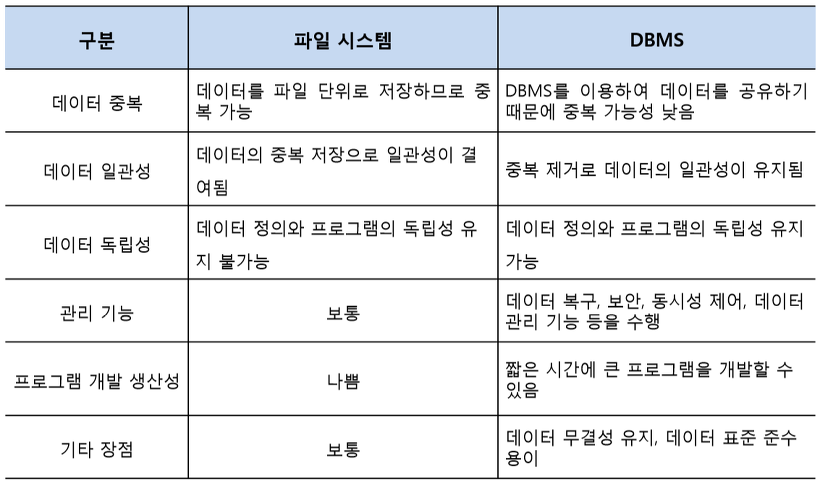
[ 파일 시스템과 DBMS의 비교 ]

[ 파일 시스템과 비교한 DBMS의 장점 ]
4. 데이터베이스 시스템의 구성
이번에는 4종류로 분리되는 데이터베이스 사용자에 대해서 알아보겠습니다.
[ 일반 사용자 ]
-
은행의 창구 혹은 관공서의 민원 접수처 등에서 데이터를 다루는 업무를 하는 사람
-
프로그래머가 개발한 프로그램을 이용하여 데이터베이스에 접근하는 일반인
일반사용자는 그 프로그램을 사용하는 모두가 됩니다. 일반사용자는 데이터베이스가 어떻게 구성되어 있고, 어떻게 설계되어 있는지에 대해 몰라도 구현된 기능을 통해 원하는 데이터를 얻을 수 있습니다. 예를 들어 우리가 카카오톡으로 메세지를 보낸다고 할 때 우리는 사용자들에 대한 정보가 어떤 테이블로 어떻게 저장되어 있는지 몰라도 상대방에게 메세지를 전송할 수 있습니다.
[ 응용 프로그래머 ]
-
일반 사용자가 사용할 수 있도록 프로그램을 만드는 사람
-
Java, C, JSP등의 프로그래밍 언어와 SQL을 사용하여 일반 사용자를 위한 UI와 데이터를 관리하는 응용로직을 개발
응용 프로그래머 덕분에 일반사용자는 데이터베이스에 대해서 알지 못해도 원하는 업무를 수행할 수 있습니다. 여기서 UI란 User Interface로 사용자가 사용하는 화면들을 나타낸다고 이해하면 됩니다.
[ SQL 사용자 ]
-
SQL을 사용하여 업무를 처리하는 IT 부서의 담당자
-
응용 프로그램으로 구현되어 있지 않은 업무를 SQL을 사용하여 처리한다.
일반적으로 회사에서는 프로그래머와 SQL 사용자를 따로 분리합니다. SQL 사용자는 Select, Insert, Delete 등과 같은 Query문(쿼리문)을 사용하여 원하는 데이터를 추가하거나 필요한 테이블을 추가적으로 생성하곤 합니다.
[ 데이터베이스 관리자(DBA) ]
-
DataBase Administrator로, 데이터베이스 운영 조직의 시스템을 총괄하는 사람이다.
-
데이터 설계, 구현, 유지보수의 전 과정을 담당
-
데이터베이스 사용자 통제, 보안, 성능 모니터링, 데이터 전체 파악 및 관리, 데이터 이동 및 복사 등 제반 업무를 함
실제 대규모의 프로젝트를 진행하다 보면 테이블의 개수가 10개, 20개가 넘어가게 되면서 데이터베이스 시스템을 설계하는 것도 여간 복잡한일이 아니기에, DBA를 따로 둬서 데이터베이스의 설계를 맡깁니다.
[ 전체 데이터베이스 사용자 ]

[ DBMS의 기능 ]
-
데이터 정의(Definition): 데이터의 구조를 정의하고 데이터 구조에 대한 삭제 및 변경 기능을 수행함
-
데이터 조작(Manipulation): 데이터를 조작하는 프로그램이 요청하는 데이터의 삽입, 수정, 삭제 작업을 지원함
-
데이터 추출(Retrieval): 사용자가 조회하는 데이터 혹은 응용 프로그램의 데이터를 추출함
-
데이터 제어(Control): 데이터베이스 사용자를 생성하고 모니터링하며 접근을 제어함. 백업과 회복, 동시성제어 등을 지원
데이터 정의와 데이터 조작이 보면 비슷해 보이지만 한 단어 차이나는게 있습니다. 바로 데이터 정의는 데이터 구조(Table)에 대해서 작업을 하는 것이고 데이터 조작은 Table에 들어있는 혹은 Table에 넣을 데이터에 대해서 작업을 하는 것입니다.
[ 데이터 모델(Data Model) ]
-
계층 데이터 모델(hierarchical data model)
-
네트워크 데이터 모델(network data model)
-
관계 데이터 모델(relation data model)
-
객체 데이터 모델(object data model)
-
객체-관계 데이터 모델(object-relational data model)
실제로 가장 많이 사용되는 모델은 관계 데이터 모델입니다. 관계데이터모델은 서로 연관된 데이터들을 테이로 모아두는 구조인데, 오늘날 객체지향 프로그래밍언어와는 모델이 맞지 않아서 ORM(Object Relational Mapping)을 사용하는 경우가 많습니다.
( ORM에 대해서 모르시면 여기를 참고해주세요~ )
관계 데이터 모델에서는 아래의 그림에서 처럼 속성값을 사용합니다. 학생이라는 관계에서는 학번과 이름 그리고 수강하는 강좌번호라는 속성이 필요하고, 강좌라는 관계에서는 강좌번호, 강좌 이름에 대한 속성이 필요한데, 이때 학생의 강좌번호와 강좌의 강좌번호를 사용하여 두 데이터를 연결시켜줍니다.

[ 3단계 데이터베이스 구조 ]
-
외부스키마(External Schema)
-
개념스키마(Conceptual Schema)
-
내부스키마(Internal Schema
데이터베이스는 3단계의 구조로 이루어져 있는데, 각각의 스키마에 대해서 자세히 살펴보겠습니다. 그 전에 도움이 될 만한 전체 데이터베이스의 구조에 대한 그림을 보여드리도록 하겠습니다.

[ 외부 스키마 ]
-
일반 사용자나 응용 프로그래머가 접근하는 계층으로 전체 데이터베이스 중 하나의 논리적인 부분을 의미
-
여러 개의 외부 스키마가 있을 수 있음
-
서브 스키마(Sub Schema)라고도 하며, View의 개념임
외부스키마란 사용자에게 보여지는 스키마로, 겉으로 보이는 DB, Table의 형태를 의미합니다. 사용 주체나 응용에 따라서 바라보는 구조가 다를 수 있습니다. 누군가는 GUI를 이용해서 볼 수 있고, 누군가는 Select문을 이용하여 조회할 수 있는데 이 때 우리가 보게되는 것을 외부스키마라고 이해하면 됩니다. 아래의 외부스키마도 다이어그램처럼 표시되어 있지만 다른 형태로도 데이터를 볼 수 있고, 그것 역시도 외부스키마라고 합니다. 외부스키마는 개념스키마의 부분집합이 됩니다. (그렇다고 외부스키마가 조회된 결과값을 의미하는 것은 아닙니다.)

[ 개념 스키마 ]
-
전체 데이터베이스의 정의를 의미
-
통합 조직별로 하나만 존재하며 DBA가 관리함
-
하나의 데이터베이스에는 하나의 개념 스키마가 존재
개념스키마란 개발하는데 필요한 모든 데이터베이스를 정의해 놓은 것입니다. 그렇기에 우리에게 필요한 데이터만을 추출해 보는 외부스키마는 개념스키마의 부분집합이 될 수 밖에 없습니다. 개념스키마는 데이터베이스에서 매우 중요한 비중을 차지하기 때문에 하나만 존재하며 이를 DBA가 관리합니다.

[ 내부 스키마 ]
-
물리적 저장장치에 데이터베이스가 실제로 저장되는 방법의 표현
-
내부 스키마 역시 하나만 존재
-
인덱스, 데이터 레코드의 배치 방법, 데이터 압축 등에 관한 사항이 포함됨
내부스키마란 실제 구현에 관한 이야기로, 이 속성이 어떠한 형태(Integer or Varchar or 등등)이며 어느정도의 크기를 갖는지 등에 관해서 기술해둔 스키마를 의미합니다. 아래의 사진을 참고하면 쉽게 이해할 수 있습니다.

[ 매핑(Mapping) ]
-
외부/개념 매핑
-
개념/내부 매핑
외부/개념 매핑은 사용자의 외부스키마와 개념 스키마 간의 매핑(사상)을 의미하며 외부 스키마의 데이터가 개념 스키마의 어느 부분에 해당되는지 대응시키는 것이다. 개념/내부 매핑은 개념 스키마의 데이터가 내부스키마의 물리적 장치 어디에 어떤 방법으로 저장되는지를 대응시키는 것이다.
[ 논리적 데이터 독립성 ]
-
외부 스키마와 개념 스키마 사이의 독립성
-
개념스키마가 변경되어도 외부 스키마에는 영향을 미치지 않도록 지원
-
논리적 구조가 변경되어도 응용 프로그램에는 영향이 없도록 하는 개념
-
개념 스키마의 테이블을 생성하거나 변경하여도 외부 스키마가 직접 다루는 테이블이 아니면 영향이 없음
논리적 데이터 독립성의 예시를 들어 설명하면 우리가 카카오톡에서 친구들 목록을 본다고 가정합시다. 이때 카카오 선물의 빼빼로 가격이 1000원 올랐다고 하여도 우리가 직접 다루고 있는 테이블이 아니기 때문에 영향을 주지 않습니다. 이렇게 우리가 보는 외부 스키마와 개념 스키마가 서로 영향을 주지 않게 분리해 놓은 것을 논리적 데이터 독립성이라고 합니다.
[ 물리적 데이터 독립성 ]
-
개념 스키마와 내부 스키마 사이의 독립성
-
저장장치 구조 변경과 같이 내부스키마가 변경되어도 개념 스키마에 영향을 미치지 않도록 지원
-
성능 개선을 위해 물리적 저장 장치를 재구성할 경우 개념 스키마나 외부스키마에 영향이 없음
-
물리적 독립성은 논리적 독립성보다 구현하기가 쉬움
물리적 데이터 독립성의 예시를 들어 설명하면 우리가 공간의 효율성을 위해서 VARCHAR(100)의 주소라는 속성을 VARCHAR(50)으로 바꾼다고 가정할 때, 우리가 주소의 크기를 줄여도 개념 스키마에는 영향을 주지 않는데 이를 물리적 데이터 독립성이라고 합니다.
출처 : (mangkyu.tistory.com/19)
2. 관계데이터 모델
1. 관계 데이터 모델의 개념
[ 릴레이션 ]
-
릴레이션: 행과 열로 구성된 테이블
-
속성(Attribute): 세로 값으로 열(Column)이라고도 한다.
-
튜플(Tuple): 가로 값으로 행(Row)이라고도 한다.
-
차수: 속성의 수
-
카디날리티: 튜플의 수
-
인스턴스: 정의된 스키마에 따라 테이블에 실제 저장된 데이터의 집합
-
스키마: 릴레이션이 어떻게 구성되는지, 어떤 정보를 담고 있는지에 대한 기본적인 구조를 정의(첫 행 헤더)
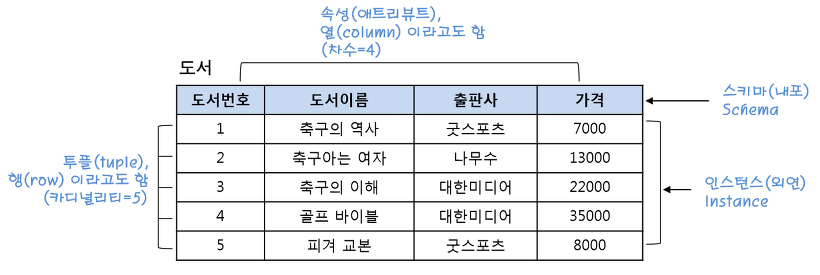
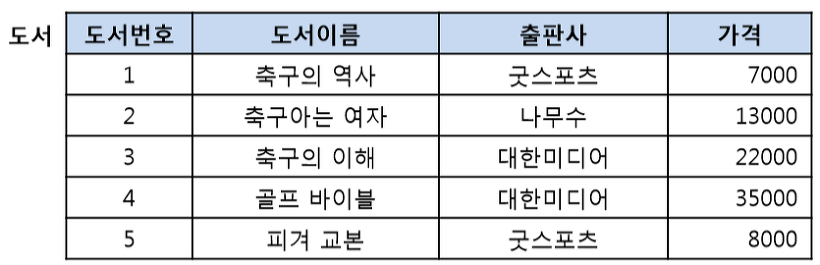
위의 그림과 같이 릴레이션이란 데이터를 행과 열로 구성된 테이블로 표현한 것입니다. 세로의 값을 속성, 가로의 값을 튜플이라고 하고 여기서 도서번호, 도서이름, 출판사, 가격때문에 차수가 4가 되며, 5개의 가로줄을 가지므로 카디날리티가 5가 됩니다.
[ 스키마의 구성요소 ]
-
속성(Attribute): 릴레이션 스키마의 열
-
도메인(Domain): 속성이 가질 수 있는 값의 집합
-
차수(Degree): 속성의 개수
위의 그림에서 속성은 도서번호, 도서이름, 출판사, 가격 그리고 차수는 4가 되는데 그렇다면 도메인은 무엇일까요? 도메인은 쉽게 말해 문법적인 개념과 같습니다. 예를 들면 Integer, Varchar(10)과 같이 값이 가질수 있는 범위 및 집합을 의미합니다.
이러한 스키마는 릴레이션 이름(속성1: 도메인, 속성2: 도메인2, ....) 이런식으로 표현하는데 일반적으로는 도메인을 제외하고 릴레이션 이름과 속성만을 적어서 도서(도서번호, 도서이름, 출판사, 가격)과 같이 표현합니다.
[ 인스턴스의 구성요소 ]
-
튜플(Tuple): 릴레이션의 행
-
카디날리티(Cardinality): 튜플의 수
여기서 투플이 가지는 속성의 개수는 릴레이션 스키마의차수와 동일하고, 릴레이션 내의 모든 튜플은 서로 중복되지 않아야 합니다. 예를 들어 설명하자면 튜플이 이름: '홍길동', 성별: '남자', 연락처: '010-1234-5678'과 같이 3개의 속성을 가지면 릴레이션 스키마 역시도 3개의 차수를 가져야 하며, 한 릴레이션 내에서 '홍길동', 성별: '남자', 연락처: '010-1234-5678'이 같은 내용으로 두번 나오면 안된다는 것입니다.
[ 릴레이션의 특징 ]
-
속성은 단일 값을 가진다
-
속성은 서로 다른 이름을 가진다
-
한 속성의 값은 모두 같은 도메인 값을 가진다
-
속성의 순서는 상관이 없다
-
릴레이션 내의 중복된 튜플은 허용하지 않는다
-
튜플의 순서는 상관없다
기본적으로 속성은 단일값을 가져야 합니다. 예를 들어 아래와 같은 릴레이션에서 하나의 책은 하나의 가격을 가져야지 7000, 8000과 같이 2개의 값을 동시에 가질 수 없음을 의미하고, 이것을 쪼개지지 않는 하나의 값만 가진다고 하여 원자값을 가진다고도 얘기합니다. 또한 한 릴레이션 내에서 이름, 이름, 이름 과 같이 동일한 속성이름은 올 수 없으며, 가격이 정수의 값을 가진다면 가격에는 '칠천원'과 같은 VARCHAR형태의 값이 올 수는 없습니다. 속성의 순서나 튜플의 순서는 무관하고, 아래의 그림에서 보이듯이 모든 속성의 값이 동일한 튜플은 한 릴레이션내에 존재할 수 없습니다.

[ 관계 데이터 모델 ]
-
릴레이션
-
제약조건
-
관계대수
관계 데이터 모델은 데이터를 2차원 테이블 형태인 릴레이션으로 표현한 것으로 릴레이션에 대한 제약조건(Constraints)와 관계 연산을 위한 관계대수(Algerbra)를 정의하였습니다. 그리고 이러한 관계 데이터 모델을 컴퓨터에 구현하면 관계 데이터베이스 시스템이 됩니다.
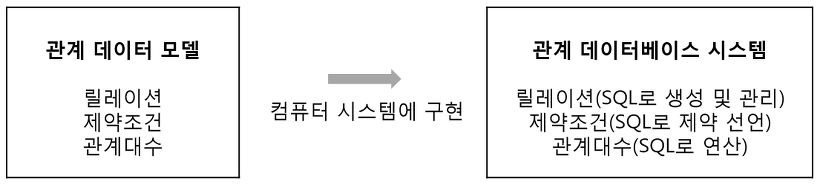
2. 무결성 제약조건
[ 키(KEY) ]
-
특정 튜플을 식별할 때 사용하는 속성 혹은 속성의 집합
-
키가 되는 속성(혹은 속성의 집합)은 값이 반드시 달라서 튜플들을 구별할 수 있어야 함
-
키는 릴레이션간의 관계를 맺는 데도 사용됨
한 릴레이션에서 중복되는 튜플들은 존재할 수 없습니다. 그러므로 각각의 튜플에 포함된 속성들 중 어느 하나(혹은 하나 이상)은 값이 달라져야 하고 각각의 튜플을 식별하는 역할을 키(Key)가 담당합니다. 일반적으로 키는 단일 속성으로 지정하지만 아래의 그림처럼 그렇지 못하는 경우에는 두개 이상의 속성을 묶어 키로 사용합니다. 아래의 릴레이션에서는 (고객번호, 도서번호) 나 (고객번호, 주문일자)와 같은 집합을 키로 사용할 수 있습니다.

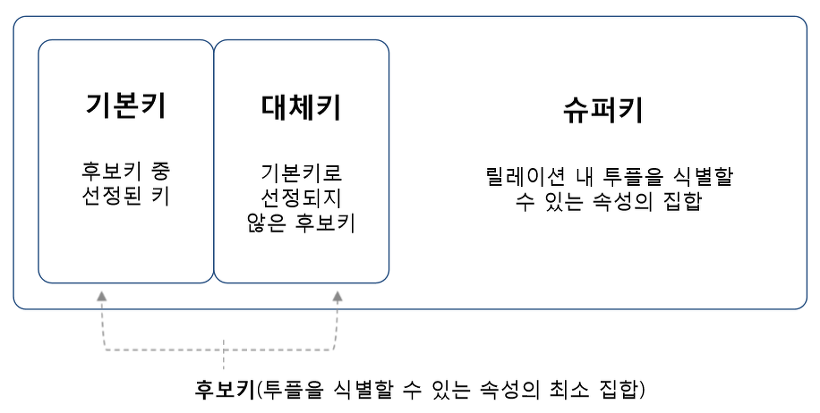
[ 슈퍼키 ]
-
퓨플을 유일하게 식별할 수 있는 하나의 속성 혹은 속성의 집합
튜플을 식별할 수 있으면 모두 슈퍼키가 될 수 있습니다. 아래와 같은 고객 릴레이션의 경우에는 이름이나 주소(가족 관계)는 동일한 값이 올 수 있고, 핸드폰의 경우에는 핸드폰이 없는 사람도 있을 수가 있으므로 고객번호 또는 주민번호가 슈퍼키가 될 수 있습니다. 그러므로 고객 릴레이션은 고객번호 또는 주민번호를 포함한 모든 속성의 집합이 슈퍼키가 될 수 있습니다.
(주민번호), (주민번호, 이름), (고객번호, 이름, 주민번호, 주소, 핸드폰) 등 여러 개가 슈퍼키가 될 수 있습니다.
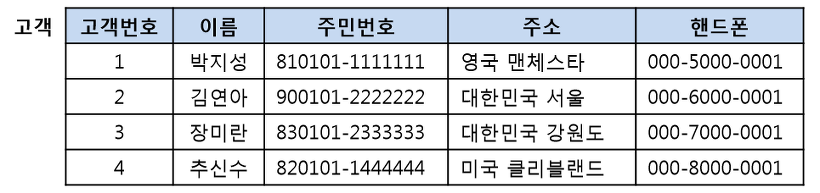
[ 후보키 ]
-
튜플을 유일하게 식별할 수 있는 속성의 최소 집합
아래와 같이 주문 릴레이션에서 단일 속성으로는 튜플을 유일하게 식별하는 것이 불가능하므로 2개의 속성을 합한(고객번호, 도서번호)가 후보키가 되며 이렇게 2개 이상의 속성으로 이루어진 키를 복합키(Composite Key)라고 합니다.
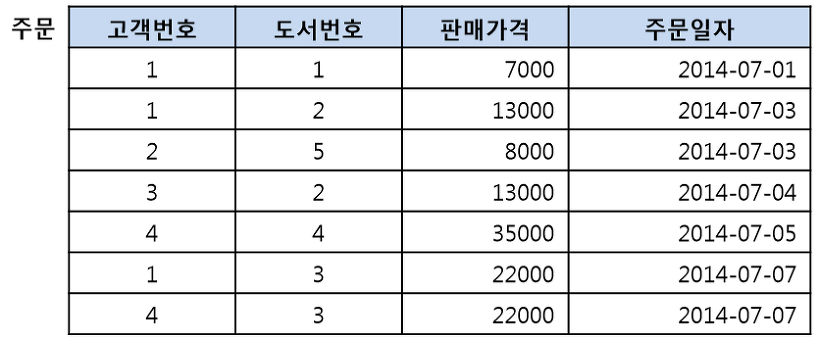
[ 기본키 ]
-
여러 후보키 중 하나를 선정하여 대표로 삼는 키
후보키가 하나뿐이라면 그 후보키를 기본키(Primary Key)로 사용하면 되고, 후보키가 여러개라면 릴레이션의 특성을 반영하여 하나를 선택하면 됩니다. 아래의 도서 릴레이션에서는 도서번호 또는 도서이름이 후보키가 되고, 두 속성 중 하나의 속성을 기본키로 선정하면 됩니다.(도서의 이름이 중복되지 않는다고 가정) 릴레이션 스키마를 표현할 때 기본키는 밑줄을 그어 표시합니다. 도서 릴레이션의 경우에는 도서(도서번호, 도서이름, 출판사, 가격)처럼 표시하면 됩니다.
[ 기본키 선정 시 고려사항 ]
-
릴레이션 내 튜플을 식별할 수 있는 고유한 값을 가져야함
-
NULL값은 허용하지 않음
-
키 값의 변동이 일어나지 않아야 함
-
최대한 적은 수의 속성을 가진것이여야 함
-
향후 키를 사용하는 데 있어서 문제 발생 소지가 없어야 함
기본키가 NULL값이 되면 다른 튜플과 식별할 수 없으므로 안됩니다. 또한 키 값의 변동이 일어나지 않아야 하는 이유는 기본키가 변경되면 릴레이션내에서 기본키를 제외하고 나머지 속성이 같았던 튜플이 기본키를 바꿈으로 중복될 수 있기 때문입니다.
[ 대체키 ]
-
기본키로 선정되지 않은 후보키
대체키(Alternate Key)는 기본키로 선정되지 않은 후보키로 고객 실레이션에서 고객번호와 주민번호 중 고객번호를 기본키로 정하면 주민번호가 대체키가 됩니다.
[ 외래키 ]
-
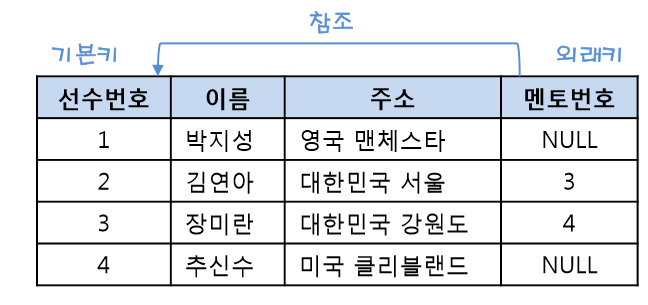
다른 릴레이션의 기본키를 참조하는 속성
위에서 키는 관계를 맺는데 활용될 수 있다고 하였는데, 외래키(Foreign Key)가 바로 그런 경우입니다. 주문 릴레이션에서 우리는 고객 릴레이션의 기본키인 고개번호와 도서릴레이션의 기본키인 도서번호를 참조하여 쓰는데 주문릴레이션에서는 고객번호와 도서번호가 외래키가 되고, 주문번호가 기본키(Primary Key)가 됩니다.

외래키를 사용할 때 참조하는 릴레이션과 참조되는 릴레이션이 다를 필요는 없습니다. 즉, 한 릴레이션에서 자기자신의 기본키를 외래키로도 가질수가 있습니다. 아래의 그림에서는 선수번호라는 기본키를 자기 자신의 릴레이션에서 멘토번호로 참조하고 있습니다. 멘토릴레이션에는 이미 선수번호라는 기본키가 존재하기 때문에 외래키는 NULL값이 되어도 상관이 없습니다.
[ 요약 ]
[ 무결성 제약조건 ]
-
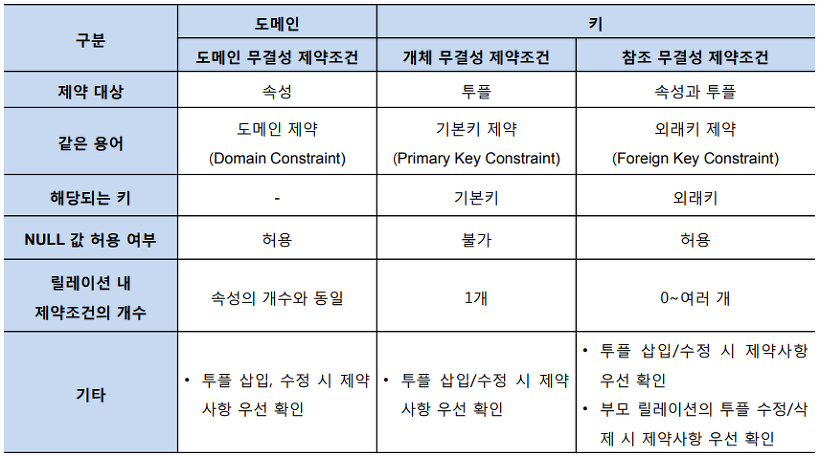
데이터 무결성(Integrity)은 데이터베이스에 저장된 데이터의 일관성과 정확성을 지키는 것을 말함
-
도메인 무결성 제약조건
-
개체 무결성 제약조건
-
참조 무결성 제약조건
도메인 무결성 제약조건은 도메인 제약(Domain Constraint)이라고도 하며, 릴레이션 내의 튜플들이 각 속성의 도메인에 지정된 값만을 가져야 한다는 조건입니다. SQL문에서 데이터 형식(Type), 널(Null/Not Null), 기본 값(Default), 체크(Check) 등을 사용하며 지정할 수 있습니다. 예를 들어 VARCHAR형으로 선언된 Name이라는 변수에는 정수형 Integer 값이 올 수 없는 경우를 의미합니다. 개체 무결성 제약조건은 기본키 제약(Primary Key Constraint)라고도 합니다. 릴레이션은 기본키를 지정하고 그에 따른 무결성 원칙 즉, 기본키는 NULL값을 가져서는 안되며 릴레이션 내에 오직 하나의 값만 존재해야 한다는 조건입니다. 기본키는 릴레이션내에서 튜플들을 구별할 수 있게 해주는 속성이므로 자연스럽게 개체 무결성 제약조건이 등장하게 되었습니다. 참조 무결성 제약조건은 외래키 제약(Foreign Key Constraint)라고도 하며, 릴레이션 간의 참조 관계를 선언하는 제약조건입니다. 자식 릴레이션의 외래키는 부모 릴레이션의 기본키와 도메인이 동일해야 하며, 자식 릴레이션의 값이 변경될 때 부모 릴레이션의 제약을 받는다는 것입니다. 자세한 내용은 아래에서 설명하도록 하겠습니다.
[ 개체 무결성 제약조건 ]
-
삽입: 기본키 값이 같으면 삽입이 금지됨
-
수정: 기본키 값이 같거나 NULL로도 수정이 금지됨
-
삭제: 특별한 확인이 필요하지 않으며 즉시 수행함
아래의 그림과 같이 학번을 기본키로 갖는 릴레이션에서 이미 학번 501을 가진 학생이 존재할 때 중복된 학번 501을 가진 학생을 삽입하려고 하거나 501로 다른 학생의 학번을 수정하려고 하거나, 학번이 NULL값인 튜플을 삽입하려고 하는 경우에 삽입이 거부됩니다. 그에 반해 삭제 연산은 기본키의 중복 또는 NULL의 염려가 없으므로 즉시 수행됩니다.

[ 참조 무결성 제약조건 ]
-
부모릴레이션에 삽입: 정상적으로 진행됨
-
자식릴레이션에 삽입: 참조받는 테이블에 외래키 값이 없으므로 삽입 금지
-
부모릴레이션의 삭제: 참조하는 테이블을 같이 삭제할 수 있어서 금지하거나 추가작업이 필요
-
자식릴레이션의 삭제: 바로 삭제 가능함
-
수정: 삭제와 삽입의 연속 수행으로 각 삭제와 삽입의 제약을 고려하여 진행됨
예를 들어 아래의 릴레이션에서 부모에 3001의 학과코드를 가진 학과를 추가하는 것은 문제가 없지만 자식 릴레이션에 부모 릴레이션에 존재하지 않는 3001의 학과코드를 삽입하려고 하는 경우에는 문제가 발생합니다. 부모릴레이션에서 삭제를 하는 경우에는 해당 키를 다른 릴레이션에서 사용하고 있을 수 있으므로 삭제에 제한이 걸리지만 자식릴레이션은 바로 삭제를 할 수 있습니다. 수정 연산은 부모 릴레이션의 수정이 일어날 경우 삭제 옵션에 따라 처리된 후 문제가 없으면 다시 삽입 제약조건에 따라 처리됩니다.

3. 관계 대수(Relation Algebra)
[ 관계대수 ]
-
관계대수: 릴레이션에서 원하는 결과를 얻기 위해 연산을 이용하여 질의하는 방법을 기술하는 언어
-
관계대수는 어떤 데이터를 어떻게 찾는지에 대한 처리 절차를 명시하는 절자적인 언어로, DBMS 내부의 처리 언어로 사용됨
-
관계해석: 어떤 데이터를 찾는지만 명시하는 선언적인 언어로 관계대수와 함께 관계 DBMS의 표준 언어인 SQL의 이론적 기반 제공
-
관계대수와 관계해석은 모두 관계 데이터 모델의 중요한 언어이며 동일한 표현능력을 가지고 있음
A= {2, 4}, B={1, 3, 5} 일 때 AxB = { (2,1), (2,3), (2,5), (4,1), (4,3), (4,5)} 이며 릴레이션 R은 타티전 프로덕트(Cartesian Product)의 부분집합으로 정의됩니다. 예를 들면 R1 = { (2,1), (4,3) } , R2 = { (2,1), (2,3), (4,5) } 원소 개수가 n인 집합 S의 부분집합의 개수는 2n2n이므로, 카티전 프로덕트 AxB의 부분집합의 개수는 2|A|∗|B|2|A|∗|B| 입니다. 카티전 프로덕트의 기초 집합 A, B 각각이 가질 수 있는 값의 범위를 도메인(Domain)이라고 하며 A의 도메인은 {2, 4}가 됩니다. 릴레이션도 역시 집합이므로 합집합, 교집합, 카티전 프로덕트 등의 연산을 수행할 수 있습니다.
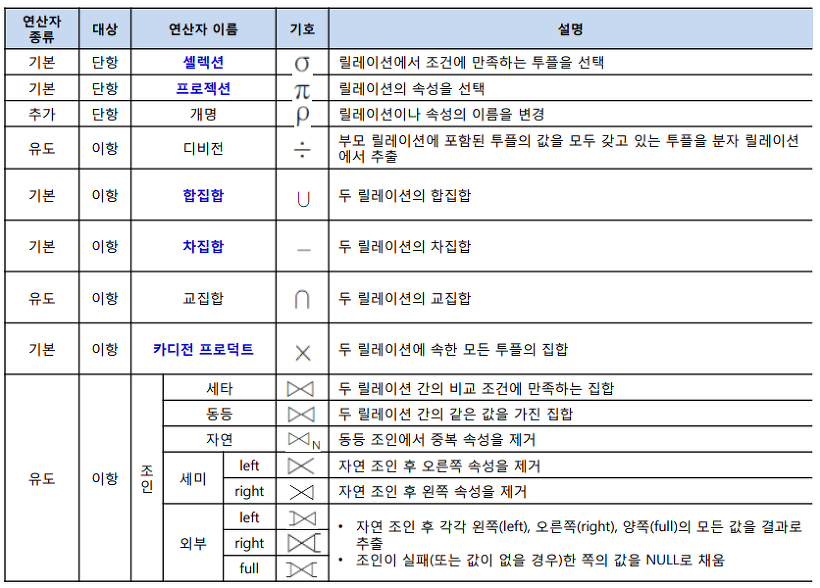
[ 관계대수 연산 ]
-
단항 연산자: 연산자<조건> 릴레이션
-
이항 연산자: 릴레이션1 연산자<조건> 릴레이션2
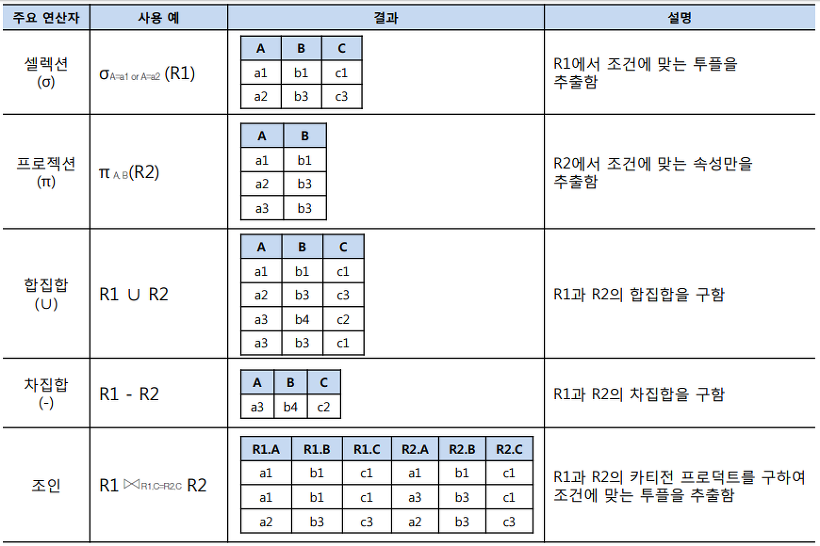
[ 조인(Join) ]
-
두 릴레이션의 공통 속성을 기준으로 속성 값이 같은 튜플(Tuple)을 수평으로 결합하는 연산
-
조인을 수행하기 위해서는 두 릴레이션의 조인에 참여하는 속성이 서로 동일한 도메인으로 구성되어야 함
-
조인 연산의 결과는 공통 속성의 속성 값이 동일한 튜플만을 반환함
-
세타조인, 동등조인, 자연조인, 세미조인, 외부조인 등이 존재
세타조인(theta join)은 조인에 참여하는 두 릴레이션의 속성 값을 비교하여 조건을 만족하는 투플만 반환합니다. 동등 조인(equi join)은 세타조인서 =연산자를 사용한 조인을 지칭합니다. 자연 조인(Natural join)은 동등 조인에서 조인에 참여한 속성이 두 번 나오지 않도록 두 번째 속성을 제거한 결과를 반환합니다. 외부 조인(Outer Join)은 자연조인 시 조인에 실패한 튜플을 모두 보여주되 값이 없는 대응 속성에는 NULL 값을 채워서 반환합니다. 모든 속성을 보여주는 기준 릴레이션의 위치에 따라 왼쪽 외부조인, 오른쪽 외부조인, 완전 외부조인으로 나뉩니다. 세미 조인(Semi join)은 자연 조인을 한 후 두 릴레이션 중 한쪽 릴레이션의 결과만 반환하며 기호에서 닫힌 쪽 릴레이션의 튜플만 반환합니다.

[ 디비전(Division) ]
-
릴레이션의 속성 값의 집합으로 연산을 수행함
-
형식: R ÷÷ S

출처 : (mangkyu.tistory.com/21)
3. SQL 기초
1. SQL학습을 위한 준비
[ SQL과 일반 프로그래밍 언어 ]

2. SQL 개요
[ SQL기능에 따른 분류 ]
-
데이터 정의어(DDL)
-
데이터 조작어(DML)
-
데이터 제어어(DCL)
데이터 정의어는 테이블이나 관계의 구조를 생성하는데 사용하며 CREATE, ALTER, DROP문 등이 있습니다. 데이터 조작어는 테이블에 데이터를 검색, 삽입, 수정, 삭제하는데 사용하며 SELECT, INSERT, DELETE, UPDATE문 등이 있습니다. 여기서 SELECT 문은 특별히 Query문(질의어)라고도 합니다. 데이터 제어어는 데이터의 사용 권한을 관리하는데 사용하며, GRANT, REVOKE문 등이 있습니다. SQL문의 내부적 실행순서는 아래와 같습니다.

3. 데이터 조작어 - 검색
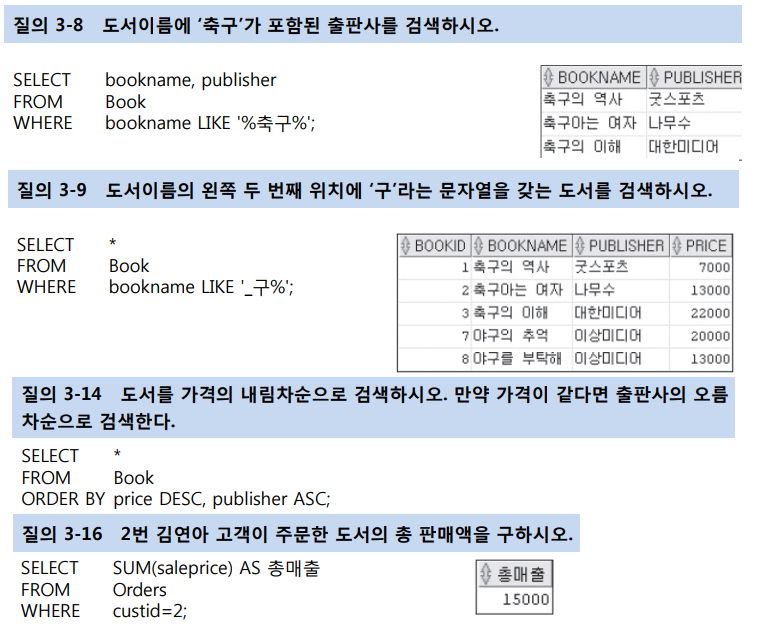
[ SELECT 문 ]
-
SELECT bookname, publisher (속성 이름)
-
FROM Book (테이블 이름)
-
WHERE price>=10000; (검색 조건)
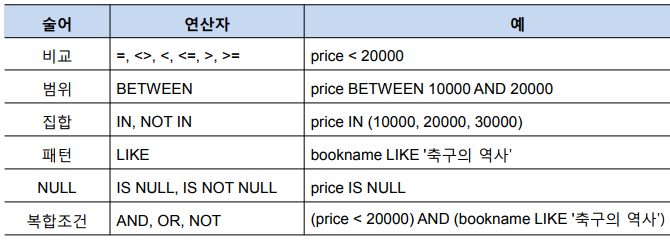
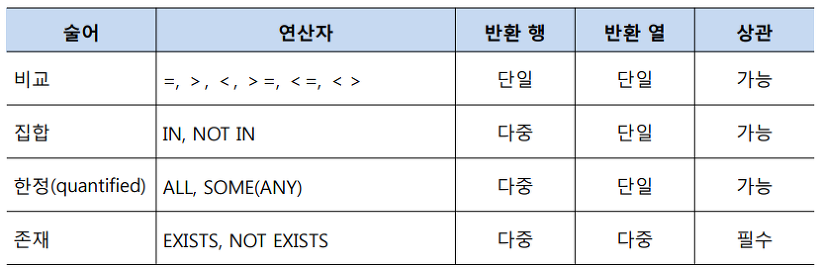
WHERE절에 조건으로 사용할 수 있는 술어는 다양하며 아래의 표에서 필요에 따라서 참고하면 됩니다.

[ 연산의 예시 ]

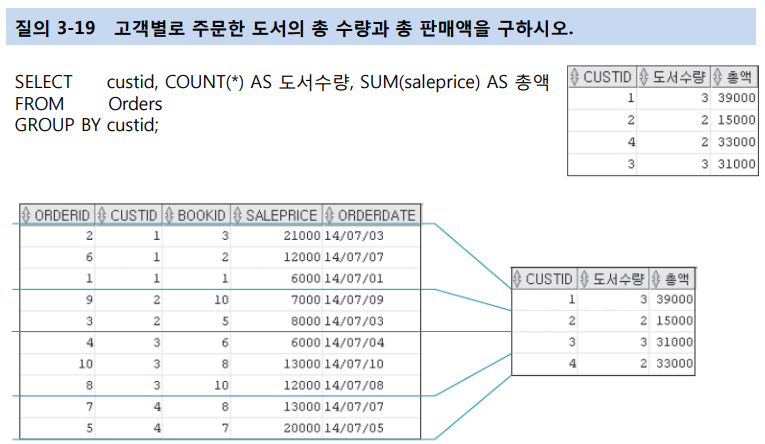
[ 조인(Join) 연산 ]

[ 부속질의(Subquery) ]
-
상관 부속질의(Correlated subquery)는 상위 부속질의의 튜플을 이용하여 하위 부속질의를 계산함
-
상위 부속질의와 하위 부속질의가 독립적이지 않고 서로 관련을 맺고 있음

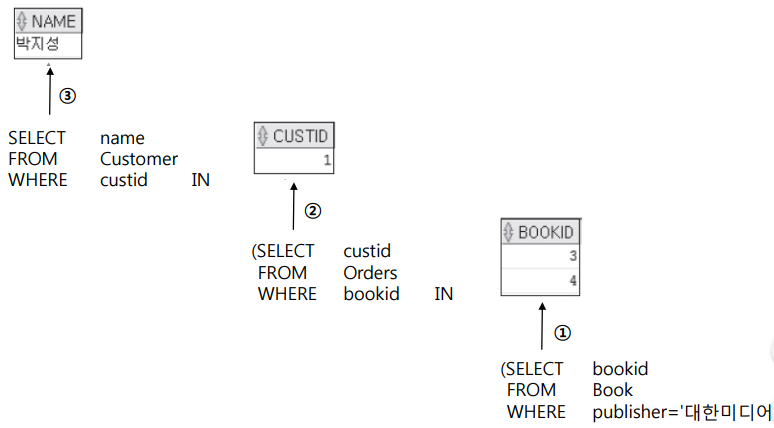
[ EXISTS ]
-
EXISTS는 원래 단어에서 의미하는 것과 같이 조건에 맞는 튜플이 존재하면 결과에 포함시킴
-
즉 부속질의문의 어떤 행이 조건에 만족하면 참임
-
반면 NOT EXISTS는 부속질의문의 모든 행이 조건에 만족하지 않을 때만 참임

4. 데이터 정의어
[ CREATE 문 ]
-
테이블을 구성하고, 속성과 속성에 관한 제약을 정의하며, 기본키 및 외래키를 정의하는 명령
-
PRIMARY KEY는 기본키를 정할 때 사용하고, FOREIGN KEY는 외래키를 지정할 때 사용하며, ON UPDATE와 ON DELETE는 외래키 속성의 수정과 튜플 삭제 시 동작을 나타냄

[ ALTER 문 ]
-
ALTER문은 생성된 테이블의 속성과 속성에 관한 제약을 변경하며, 기본키 및 외래키를 변경함
-
ADD, DROP은 속성을 추가하거나 제거할 때 사용함
-
MODIFY는 속성의 기본값을 설정하거나 삭제할 때 이용함

[ DROP 문 ]
-
DROP문은 테이블을 삭제하는 명령
-
테이블의 구조와 데이터를 모두 삭제하므로 사용에 주의해야 함(데이터만 삭제하려면 DELETE)

5. 데이터 조작어
[ INSERT 문 ]
-
테이블에 새로운 튜플을 삽입하는 명령
-
대량삽입(Bulk Insert)란 한번에 여러 개의 튜플을 삽입하는 방법

[ UPDATE 문 ]
-
UPDATE문은 특정 속성 값을 수정하는 명령이다.
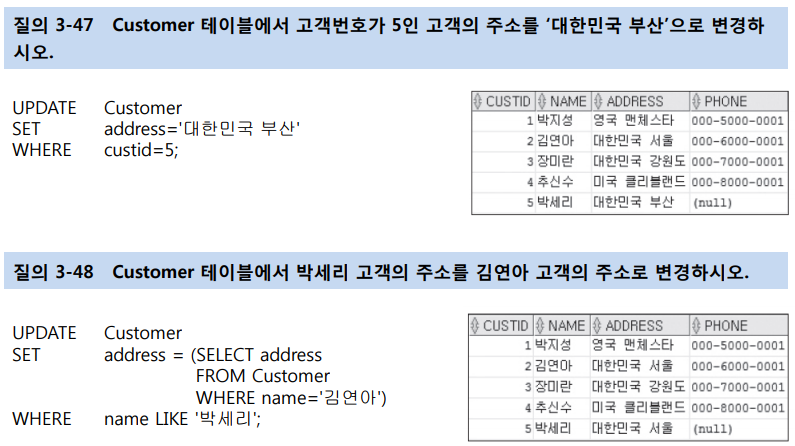
[ DELETE 문 ]
-
DELETE문은 테이블에 있는 기존 튜플을 삭제하는 명령임.

출처 : (mangkyu.tistory.com/24)
4. SQL 고급
1. 내장함수
[ 내장 함수 ]
-
SQL에서는 함수의 개념을 사용하는데, 수학의 함수와 마찬가지로 특정 값이나 열의 값을 입력 받아 그 값을 계산하여 결과 값을 돌려줌.
-
SQL의 함수는 DBMS가 제공하는 내장 함수(built-in function)와 사용자가 필요에 따라 직접 만드는 사용자 정의 함수(user-defined function)로 나뉨.
-
SQL내장함수는 상수나 속성 이름을 입력 값으로 받아 단일 값을 결과로 반환함.
-
모든 내장 함수는 최초에 선언될 때 유효한 입력 값을 받아야 함.

[ 숫자 함수 ]
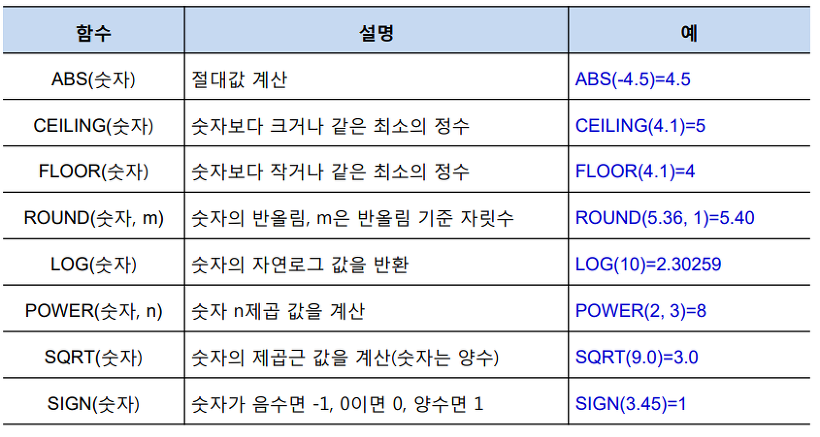

[ 문자함수 ]


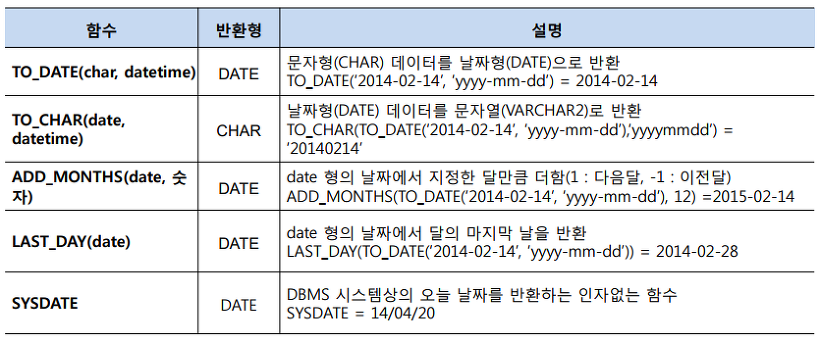
[ 날짜 및 시간 함수 ]

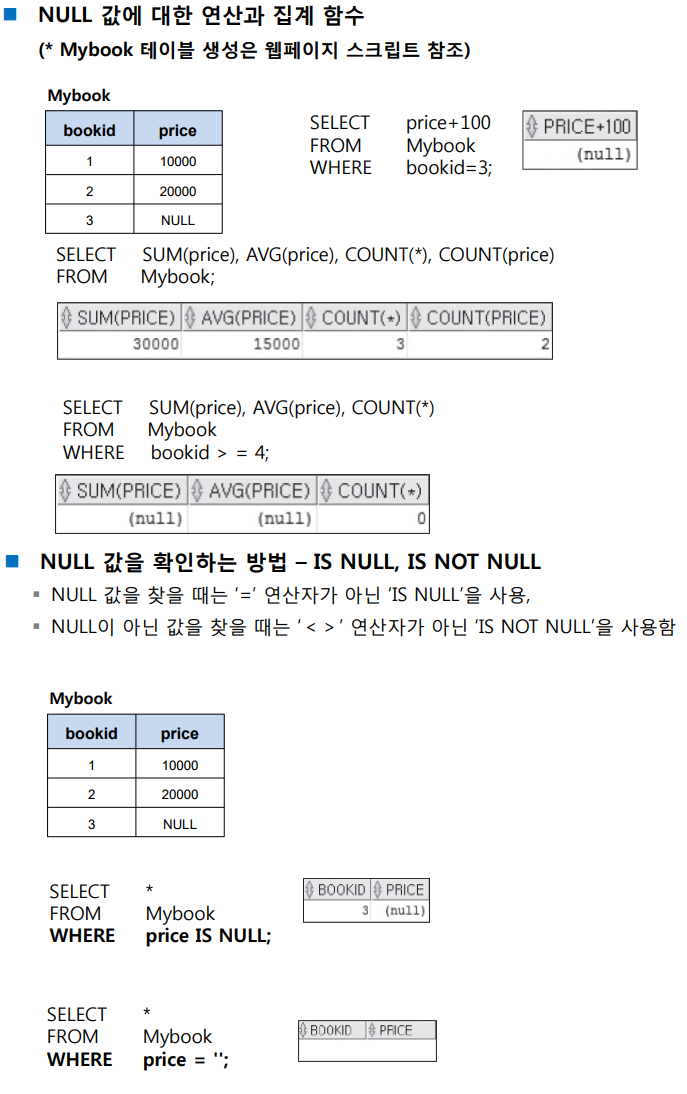
[ NULL 값 처리 ]
-
NULL은 아직 지정되지 않은 값으로 0 또는 ''(빈문자) 그리고 ' '(공백) 과는 다른 특별한 값이다.
-
NULL값은 비교 연산자로 비교가 불가능함.
-
NULL값의 산술 연산을 수행하면 결과 역시 NULL 값으로 반횐됨.
-
NULL+숫자 연산의 결과는 NULL
-
집계 함수 계산 시 NULL이 포함된 행은 집계에서 빠짐.
-
해당되는 행이 하나도 없을 경우 SUM, AVG 함수의 결과는 NULL이 되며, COUNT함수의 결과는 0.

[ ROWNUM ]
-
내장 함수는 아니지만 자주 사용되는 문법임.
-
오라클에서 내부적으로 생성되는 가상 컬럼으로 SQL 조회 결과의 순번을 나타냄.
-
자료를 일부분만 확인하여 처리할 때 유용함.

2. 부속질의
[ 부속질의(Subquery) ]
-
하나의 SQL문 안에 다른 SQL 문이 중첩된 질의를 말함.
-
다른 테이블에서 가져온 데이터로 현재 테이블에 있는 정보를 찾거나 가공할 때 사용함.
-
보통 데이터가 대량일 대 데이터를 모두 합쳐서 연산하는 조인보다 필요한 데이터만 찾아서 공급해주는 부속질의가 성능이 더 좋음.
-
주질의(Main Query, 외부질의)와 부속질의(Sub Query, 내부 질의)로 구성됨.


[ 스칼라 부속질의(Scalar Subquery) - SELECT 부속질의 ]
-
SELECT 절에서 사용되는 부속질의로, 부속질의의 결과 값을 단일 행, 단일 열의 스칼라 값으로 반환함.
-
스칼라 부속질의는 원칙적으로 스칼라 값이 들어갈 수 있는 모든 곳에 사용 가능하며, 일반적으로 SELECT문과 UPDATE SET 절에 사용됨.
-
주질의와 부속질의와의 관계는 상관/비상관 모두 가능함.


[ 인라인 뷰(Inline View) - FROM 부속질의 ]
-
From 절에서 사용되는 부속질의.
-
테이블 이름 대신 인라인 뷰 부속질의를 사용하면 보통의 테이블과 같은 형태로 사용할 수 있음.
-
부속질의 결과 반환되는 데이터는 다중 행, 다중 열이어도 상관없음.
-
다만 가상의 테이블인 뷰 형태로 제공되어 상관 부속질의로 사용될 수는 없음.


[ 중첩질의(Nested Subquery) - WHERE 부속질의 ]
-
WHERE 절에서 사용되는 부속질의.
-
WHERE 절은 보통 데이터를 선택하는 조건 혹은 술어(predicate)와 같이 사용됨. 그래서 중첩질의를 술어 부속질의( Predicate subquery)라고도 함.
-
부속질의 결과 반환되는 데이터는 다중 행, 다중 열이어도 상관없음.
-
다만 가상의 테이블인 뷰 형태로 제공되어 상관 부속질의로 사용될 수는 없음.

3. 뷰
[ 뷰(View) ]
-
뷰(View)는 하나 이상의 테이블을 합하여 만든 가상의 테이블.
-
편리성: 미리 정의된 뷰를 일반 테이블처럼 사용할 수 있기 때문에 편리함. 또 사용자가 필요한 정보만 요구에 맞게 가공하여 뷰로 만들어 쓸 수 있음.
-
재사용성: 자주 사용되는 질의를 뷰로 미리 정의해 놓을 수 있음.
-
보안성: 각 사용자별로 필요한 데이터만 선별하여 보여줄 수 있음. 중요한 질의의 경우 질의 내용을 암호화할 수 있음.

[ 뷰의 생성 ]

[ 뷰의 수정 ]

[ 뷰의 삭제 ]

4. 인덱스(Index)
[ 데이터베이스의 물리적 저장 ]
-
데이터가 저장되는 곳: 하드디스크, SSD, USB 메모리
-
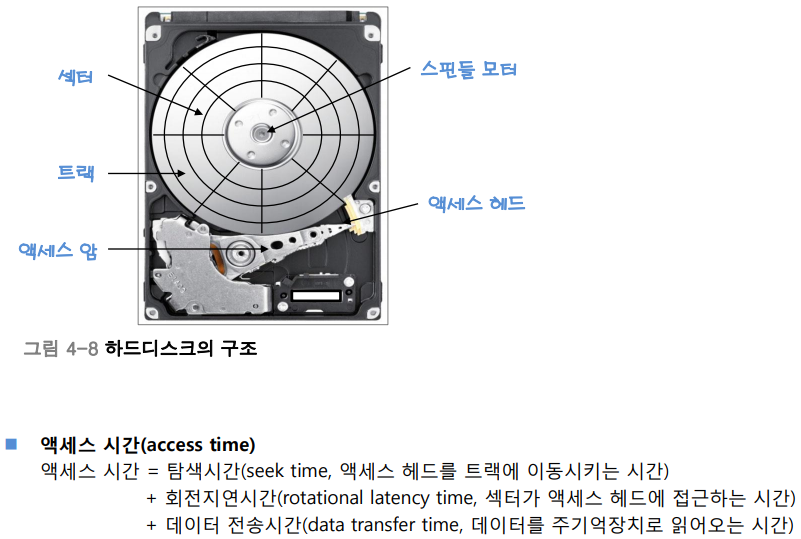
하드디스크의 3가지 특징
-
원형의 플레이트(Plate)로 구성되어 있고, 이 플레이트는 논리적으로 트랙으로 나뉘며 트랙은 다시 몇개의 섹터로 나뉨.
-
원형의 플레이트는 초당 빠른 속도로 회전하고, 회전하는 플레이트를 하드디스크의 액세스 암(arm)과 헤더가 접근하여 원하는 섹터에서 데이터를 가져옴.
-
하드디스크에 저장된 데이터를 읽어 오는 데 걸리는 시간은 모터(Motor)에 의해서 분당 회전하는 속도(RPM, Revolutions Per Minute), 데이터를 읽을 대 액세스 암이 이동하는 시간(Latency time), 주기억 장치로 읽어오는 시간(Transfer Time)에 영향을 받음.

[ 인덱스(index, 색인) ]
-
인덱스: 도서의 색인이나 사전과 같이 데이터를 쉽고 빠르게 찾을 수 있도록 만든 데이터 구조
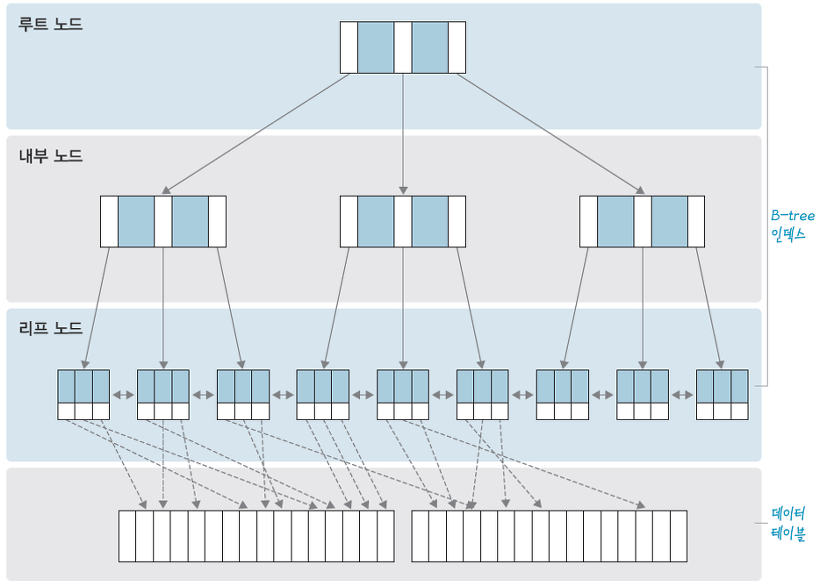
위의 그림과 같이 하나의 루트노드로부터 시작하여 인덱스들을 이용하여 데이터가 있는 테이블을 참조합니다. 인덱스가 데이터 테이블에 도달하기 전까지 인덱스를 점점 구체화시켜가며 최하위의 데이터 테이블에 도착하면 데이터를 참조합니다. B-Tree에서 데이터를 찾아가는 과정에 대해서는 아래에서 자세히 다루도록 하겠습니다!
[ 인덱스의 특징 ]
-
인덱스는 테이블에서 한 개 이상의 속성을 이용하여 생성함.
-
빠른 검색과 함께 효율적인 레코드 접근이 가능함.
-
순서대로 정렬된 속성과 데이터의 위치만 보유하므로 테이블보다 작은 공간을 차지함.
-
저장된 값들은 테이블의 부분집합이 됨.
-
일반적으로 B-tree 형태의 구조를 가짐
-
데이터의 수정, 삭제 등의 변경이 발생하면 인덱스의 재구성이 필요함.
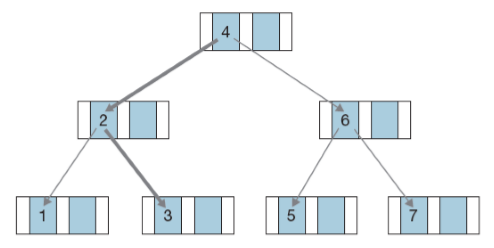
자료구조 중에서 원하는 값을 최고로 빠르게 가져올 수 있는 구조가 트리구조라고 합니다. 그래서 데이터베이스의 인덱스에서도 트리구조를 활용하는데, 속성을 인덱스로 활용하여 높은 효율성을 보여줍니다. 어떤 값을 삭제 또는 변경하는 경우에 트리의 구조가 무너져서 순서대로 정렬되지 않은 트리구조로 변질될 수 있으므로 수정, 삭제와 같은 연산을 수행하는 경우에는 인덱스를 재구성해주어야 합니다.
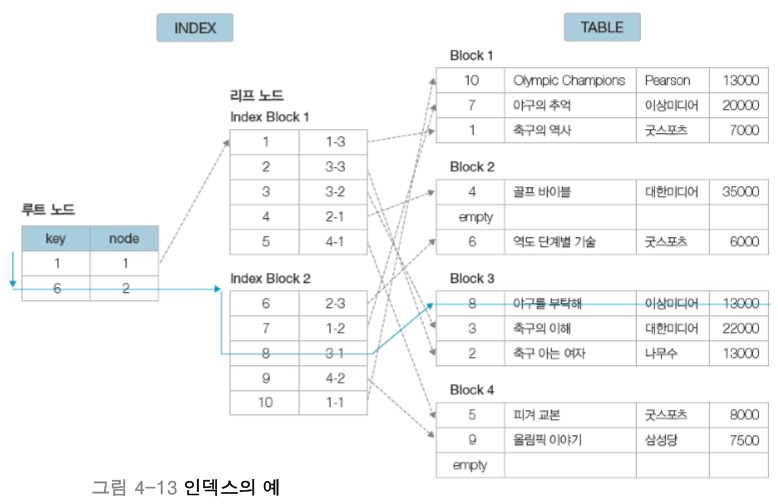
[ 인덱스의 생성 ]
-
인덱스는 WHERE절에 자주 사용되는 속성이어야 함.
-
인덱스는 Join(조인)에 자주 사용되는 속성이어야 함
-
단일 테이블에 인덱스가 많으면 속도가 느려질 수 있음
-
속성이 가공되는 경우에 사용하지 않음
-
속성의 선택도가 낮을 때 유리함
인덱스가 WHERE절에서 자주 사용되는 속성이어야 하는 이유는 자명합니다. WHERE절에 자주 사용되는 속성일수록 그 속성을 이용하여 접근을 많이 한다는 것이고 접근의 효율을 높이기 위해서는 그 속성을 인덱스로 사용하여 B-TREE에 접근하는 것이 최적이기 때문입니다. 조인도 마찬가지입니다. 하지만 무분별하게 인덱스를 많이 생성하면 효율이 느려질 수 있으므로 한 테이블에 4~5개를 권장합니다. 또한 속성이 가공된다는 것은 변경 또는 삭제의 연산을 의미하는데, 변경 또는 삭제 연산을 수행하는 경우에는 인덱스의 재구성을 필수적으로 해주어야 하므로 가공되지 않는 속성의 경우에 유리합니다. 또한 속성의 선택도가 낮을 때 즉, 속성의 모든 값이 다른 경우에, 하나의 인덱스 만을 사용하여 접근하므로 효율이 좋아집니다. 그러므로 선택도가 낮은 속성을 인덱스로 만드는 것이 유리합니다.


[ 인덱스의 재구성과 삭제 ]
-
인덱스의 재구성은 ALTER INDEX 명령을 사용한다.

출처 : (mangkyu.tistory.com/25)
5. 데이터베이스 프로그래밍
1. 데이터베이스 프로그래밍의 개념
[ 데이터베이스 프로그래밍 ]
-
프로그래밍: 프로그램을 설계하고 소스코드를 작성하여 디버깅하는 과정
-
데이터베이스 프로그래밍: DBMS에 데이터를 정의하고 저장된 데이터를 읽어와 데이터를 변경하는 프로그램을 작성하는 과정. 일반 프로그래밍과는 데이터베이스 언어인 SQL을 포함한다는 점이 다르다
데이터베이스 프로그래밍 중에서도 SQL Interface 와 Embedded Programming을 사용하는 경우가 있습니다.
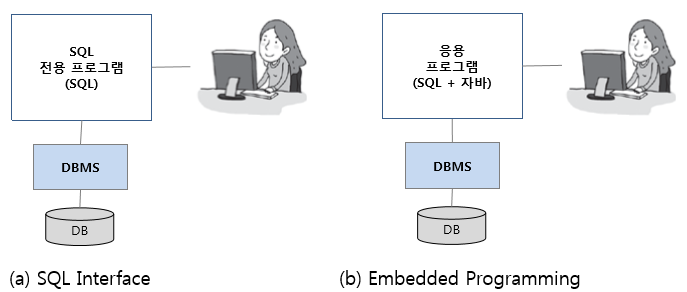
[ 데이터베이스 프로그래밍 방법 ]
-
SQL 전용 언어를 사용하는 방법
-
일반 프로그래밍 언어에 SQL을 삽입하여 사용하는 방법
-
웹 프로그래밍 언어에 SQL을 삽입하여 사용하는 방법
-
4GL (4th Generation Language)
일반적으로 기계어를 1세대, 어셈블리 언어를 2세대 그리고 절차지향 언어를 3세대 그리고 4세대언어인 4GL은 순차형 언어 이후의 프로그래밍 언어를 가리킵니다. 즉, 4GL이란 사용자 중심의 언어로 절차지향적인 틀에서 벗어난 언어 예를 들어 JAVA와 C++같은 객체 지향의 언어가 포함됩니다.
2. PL/SQL
[ PL/SQL이란? ]
-
Procedural Language/Structured Query Language로 응용 프로그램을 작성하는데 사용하는 오라클 전용 SQL 언어
-
SQL 전용 언어로 SQL문에 변수, 제어, 입출력 등의 프로그래밍 기능을 추가하여 SQL만으로 처리하기 어려운 문제 해결
-
PL/SQL 은 SQL Developer에서 바로 작성하고 컴파일한 후 결과를 실행함
-
PL/SQL에는 프로시저, 트리거, 사용자 정의 함수 등이 있다.
[ 프로시저 ]
-
프로시저를 정의하려면 CREATE PROCEDURE 문을 사용해야 한다.
-
PL/SQL은 선언부(BEGIN)와 실행부(END)로 구성된다.
-
선언부에서는 변수와 매개변수를 선언하고, 실행부에서는 프로그램 로직을 구현한다.
-
매개변수(parameter)는 저장 프로시저가 호출될 때 그 프로시저에 전달되는 값이다.
-
변수(Variable)는 저장 프로시저나 트리거 내에서 사용되는 값임
-
주석은 /*와 */ 사이 또는 -- 다음에 기술하면 된다.
프로시저는 프로그래밍에서 함수와 유사합니다. 프로시저를 실행하는데 필요한 매개변수를 받고, 프로시저의 구현에 필요한 변수는 선언부에 선언을 하고 로직은 실행부에 구성을 합니다. 그렇기에 아래의 프로시저처럼 Insert와 같이 여러번 자주 실행해야 하는 SQL문들을 프로시저로 구현해두면 상당한 편리성을 얻을 수 있습니다.

동일한 값이 있는지를 검사하기 위한 프로시저는 아래와 같이 구현할 수 있습니다. 예를 들어 같은 책 제목을 가진 도서가 있는지를 검사하는 프로시저를 작성하고자 할 때, mycount라는 변수를 두어 내가 원하는 책 제목을 가진 책들이 도서목록에 몇 개 있나 개수를 세주어야 합니다. 그러므로 Begin(선언부)에 mycount라는 변수를 선언해두고 End(실행부)에서는 If/else와 같은 제어문을 사용하여 mycount==0인 경우와 그렇지 않은 경우를 나누어 처리해주면 됩니다.

우리는 프로시저가 한 번에 한 행씩 처리하기를 원하는 경우가 있는데 이러한 경우에 커서(Cursor)를 활용하여 테이블의 행을 순서대로 가리키도록 하고, 필요한 경우에 그 행의 데이터를 추출할 수 있습니다. 커서와 관련된 키워드는 아래와 같습니다.
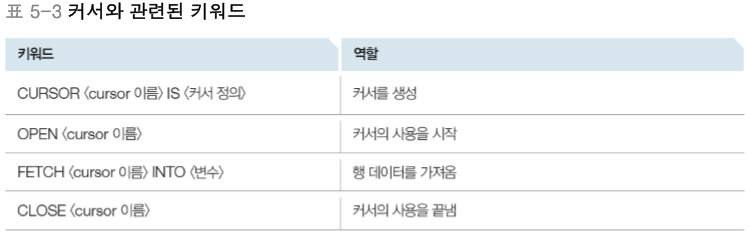
판매 도서 목록에 대한 이윤을 계산하는 프로시저를 작성한다고 할 때, 우리는 행마다 값을 확인하여 처리를 해주어야 합니다. 그래서 프로시저 선언부에서 Cursor - IS - 를 활용하여 커서를 만들어주고, Open -를 활용하여 커서를 열어주고 Fetch - INTO - 하여 데이터를 추출한 후에 반복문이 종료되면 Close 함수를 이용하여 커서의 사용을 끝내면 됩니다. 그리고 이를 전체 프로시저로 작성하면 아래와 같습니다.

[ 트리거 ]
-
트리거(Trigger)는 데이터의 변경(INSERT, DELETE, UPDATE)문이 실행될 때 자동으로 실행되는 프로시저를 의미한다.
-
트리거에는 BEFORE 트리거와 AFTER 트리거가 있다.
BEFORE 트리거란 해당 프로시저의 실행 이전에 자동으로 먼저 실행되는 프로시저이며, AFTER 트리거란 해당 프로시저가 실행된 후에 자동으로 실행되는 프로시저입니다.

아래의 그림에서는 새로운 도서가 Book테이블에 삽입된 후 백업을 위해 Book_log 테이블에 같은 내용을 삽입하는 트리거를 보여주고 있습니다. AFTER INSERT ON Book FOR EACH ROW 구문은 Book 테이블에 값이 추가되면 실행하는 트리거임을 명시해주고 있고, 실행부(END)에서는 Book_log 테이블에 데이터를 백업해두고 있습니다.

[ 사용자 정의 함수 ]
-
사용자 정의 함수는 수학의 함수와 마찬가지로 입력된 값을 가공하여 결과를 돌려준다.
아래의 함수는 판매된 도서에 대한 이익을 계산하는 함수입니다. RETURN 값이 INT 형임과 그 값이 사용자가 선언한 변수임을 적어주고 있고, 인자로는 price라는 판매 가격을 받고 있습니다.

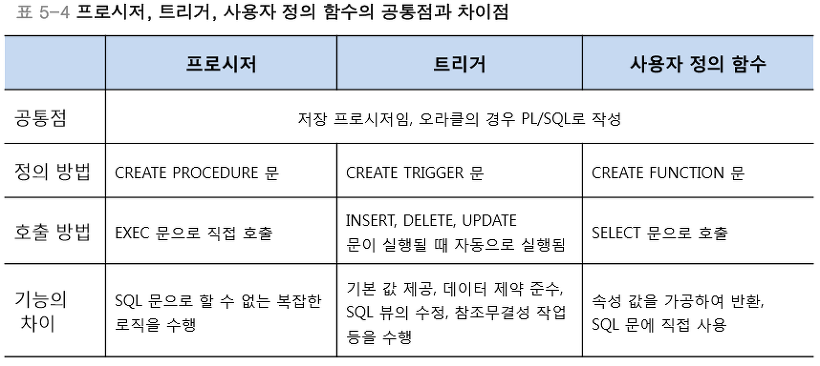
[ 프로시저, 트리거, 사용자 정의 함수 비교 ]
뒷 내용은 개인의 실습에 맡기도록 하겠습니다!
출처 : (mangkyu.tistory.com/26)
6. 데이터 모델링(Data Modeling)
1. 데이터 모델링의 개념(Data Modeling)
[ 데이터베이스 생명주기 ]
-
데이터베이스 생명주기는 데이터베이스의 생성과 운영에 관련된 특징을 의미하고 아래의 5단계로 구성된다.
-
요구사항 수집 및 분석
-
설계
-
구현
-
운영
-
감시 및 개선
요구사항 수집 및 분석의 단계에서는 사용자들의 요구사항을 듣고 분석하여 데이터베이스 구축의 범위를 정합니다. 설계 단계에서는 분석된 요구사항을 기초로 주요 개념과 업무 프로세스 등을 식별하고(개념적 설계) 사용하는 DBMS의 종류에 맞게 변환(논리적 설계)한 후, 데이터베이스 스키마를 도출(물리적 설계)합니다. 즉, 설계의 단계에서 개념적 모델링을 하여 ER다이어그램을 도출하고 이를 이용하여 관계 스키마 모델을 도출하고 이를 물리적 모델링하여 관계 스키마를 도출해냅니다. 구현의 단계에서는 설계 단계에서 생성한 스키마를 실제 DBMS에 적용하여 테이블 및 관련 객체(뷰 or 인덱스)를 만들고, 운영의 단계에서 구현된 데이터베이스를 기반으로 소프트웨어를 구축하여 서비스를 제공합니다. 그리고 감시 및 개선의 단계에서는 데이터베이스 자체의 문제점을 파악하여 개선합니다.

[ 3가지 모델링 ]
-
개념적 모델링: 개체와 개체들 간의 관계에서 ER다이어그램을 만드는 과정
-
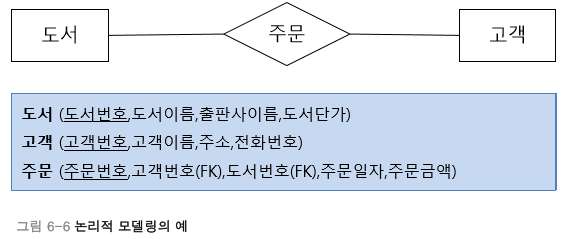
논리적 모델링: ER다이어그램을 사용하여 관계 스키마 모델을 만드는 과정
-
물리적 모델링: 관계 스키마 모델의 물리적 구조를 정의하고 구현하는 과정
정보 모델링(Information Modeling)이라고도 불리는 개념적 모델링(Conceptual Modeling)이란 요구사항을 수집하고 분석한 결과를 토대로 업무의 핵심적인 개념을 구분하고 전체적인 뼈대를 만드는 과정입니다. 즉, 개념적 모델링이란 개체(Entity)를 추출하고 개체들 간의 관계를 정의하여 ER다이어그램을 만드는 과정까지를 말합니다. 논리적 모델링이란 개념적 모델링에서 만든 ER 다이어그램을 사용하려는 DBMS에 맞게 사상(Mapping)하여 실제 데이터베이스로 구현하기 위한 관계 스키마 모델을 만드는 과정입니다. 논리적 모델링을 하는 과정에는 상세속성 추출, 정규화 수행, 데이터 표준화 수행이 있습니다. 마지막 물리적 모델링은 작성된 논리적 모델을 실제 컴퓨터의 저장 장치에 저장하기 위한 물리적 구조를 정의하고 구현하는 과정입니다. DBMS의 특성에 맞게 저장 구조를 정의해야 데이터베이스가 최적의 성능을 낼 수 있습니다. 물리적 모델링을 하는 경우에 트랜잭션, 저장공간 설계의 측면에서 3가지를 고려해주어야 하는데, 응답시간을 최소화해야하고, 동시에 많은 트랜잭션을 발생시킬 수 있어야 하며, 데이터가 저장될 공간을 효율적으로 배치해야 합니다.


2. ER모델(ER Model)
[ ER모델 ]
-
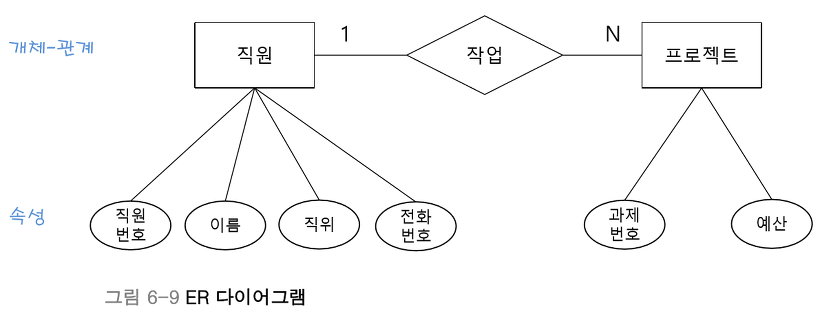
ER모델: 세상의 모든 사물을 개체(Entity)와 개체 간의 관계(Relationship)으로 표현
-
개체: 독립적인 의미를 지니고 있는 유무형의 사람 또는 사물로 개체의 특성을 나타내는 속성(Attribute)에 의해 식별된다.
-
개체끼리 서로 관계를 지닌다.
간단히 말해서 ER모델(Entity Relationship Model)은 현실 세계에서 개체들을 도출하고 개체들 사이의 관계를 기술하는 것으로, 아래의 그림을 참고하면 쉽게 이해할 수 있습니다.

우리는 ER모델으로 ER다이어그램(ER Diagram)을 만들 수 있습니다. ER다이어그램에서 개체는 ㅁ, 개체의 속성은 ㅇ 그리고 개체 사이의 관계는 ◇로 표현됩니다.
[ 개체와 개체타입 ]
-
개체(Entity): 사람, 사물, 장소, 개념, 사건과 같이 유무형의 정보를 가지고 있는 독립적인 실체
-
데이터베이스에서 주로 다루는 개체: 낱개로 구성된 것으로 각각 데이터 값을 가지며 데이터 값이 변하는 것
-
비슷한 속성의 개체 타입을 구성하며 개체 집합으로 묶임
데이터베이스에서 개체란 데이터를 가진 대상이 됩니다. 그리고 데이터들이 가진 공통의 속성이 개체타입(Entity Type)이 되며 여러개의 개체가 모여있는 것을 개체 집합(Entity Set)이라고 합니다. 예를 들어 '스타크래프트', '피파온라인', '배틀 그라운드'와 같은 개체들이 있다고 하면 이 개체들을 모아둔 집합을 개체 집합이라고 하며 게임이라는 공통된 것이 이 개체타입이 됩니다. 아래에서는 도서에 대한 개체의 예시를 보여주고 있습니다.
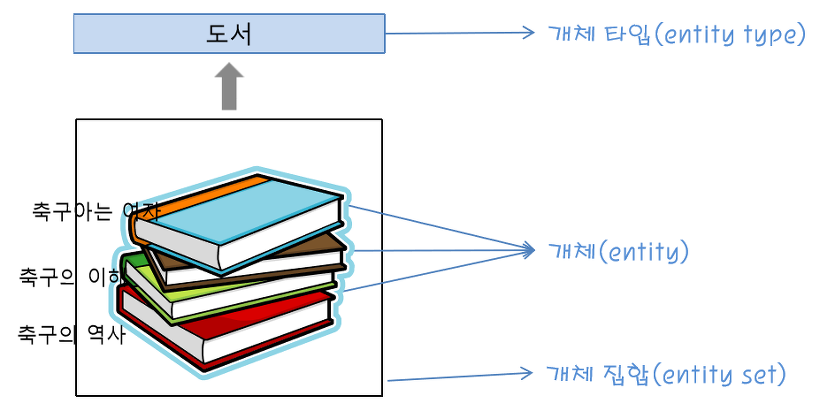
위에서 언급하였듯 ER 다이어그램상에서 개체 타입은 직사각형으로 표현됩니다. 개체에는 약한 개체와 강한 개체가 있는데 강한 개체란 다른 개체의 도움 없이 독자적으로 존재할 수 있는 개체를 의미하고 우리가 생각하는 일반적인 개체로 이해하면 됩니다. 약한 개체란 독자적으로 존재할 수 없으며 반드시 상위 개체 타입을 가지며 2중 ㅁ를 활용하여 그려줍니다.

[ 속성(Attribute) ]
-
속성은 개체가 가진 성질을 의미한다.
-
속성은 기본적으로 타원으로 표현하며 개체 타입을 나타내는 직사각형과 실선으로 연결된다.
-
속성의 이름은 타원의 중앙에 표기함.
-
속성이 개체를 유일하게 식별할 수 있는 키일 경우 속성 이름에 밑줄을 그음.
예를 들어 도서라는 개체타입이 있다고 가정하면 도서의 속성에는 책이름, 판매가격, 출판사 등이 있을 수 있습니다. 그리고 도서의 이름은 개체를 유일하게 식별할 수 있는 키이므로 타원 안에 밑줄을 그어 적어줍니다.
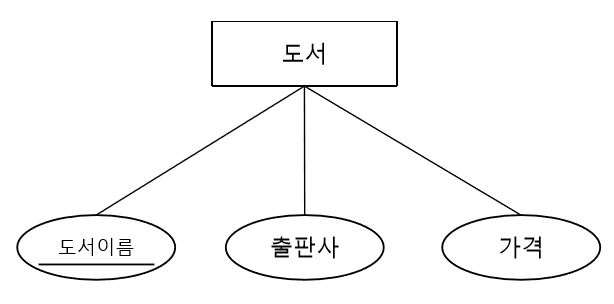
[ 관계와 관계 타입 ]
-
관계(Relationship)란 개체 사이의 연관성을 나타내는 개념이다.
-
관계 타입(Relationhip Type)이란 개체 타입과 개체 타입 간의 연결 가능한 관계를 정의한 것이다.
-
관계 집합(Relationship set)은 관계로 연결된 집합을 의미한다.
예를 들어 도서와 고객이라는 개체가 있다고 가정합시다. 고객은 도서를 보고 주문을 하므로 고객과 도서 사이에는 주문이라는 관계가 생길 수 있습니다. 여기서 관계에 묶여있는 개체의 개수에 따라서 1진 관계, 2진 관계, 3진 관계 그리고 n진 관계라고 얘기합니다. 아래의 그림에서 주문이라는 관계는 2진 관계라고 얘기할 수 있습니다.

그리고 관계에는 관계 대응수(Cardinality)라는 개념이 있는데 두 개체 타입의 관계에 실제로 참여하는 개별 개체수를 관계 대응수라고 정의합니다. 관계 대응수는 일대일 관계, 일대다 관계, 다대일 관계, 다대다 관계가 있습니다. 한 학생이이 하나의 학번을 갖는 것을 일대일 관계, 한개의 학과에 여러 명의 학생이 있는 것을 일대다 관계, 여러 명의 학생이 여러 개의 강좌를 듣는 것을 다대다 관계라고 합니다.
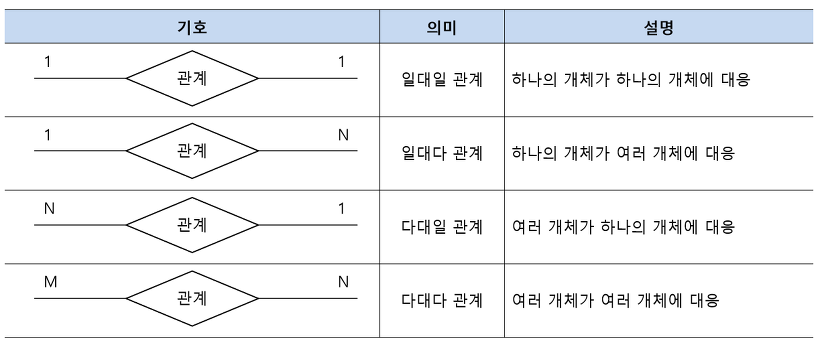
관계 대응수에서 1, N, M은 각 개체가 관계에 참여하는 최댓값을 의미합니다. 하지만 개체의 최솟값을 표시하지 않는다는 단점이 있는데, 이를 보완하기 위해 ER다이어그램에서 최솟값과 최댓값을 (최솟값, 최댓값)으로 표기합니다.

학과와 학생의 관계는 1개의 학과에 여러 명의 학생이 있을 수 있기 때문에1대 N의 관계입니다. 그리고 이를 (최솟값, 최댓값)으로 표현하면 아래와 같습니다. 학과에는 반대 쪽에 (1,1) 이 있는 것 그리고 학생에는 반대쪽에 (0, *)이 있는 것으로 보아 하나의 학과에는 여러명의 학생이 속할 수 있으며 최솟값이 0인 것을 보아 학과에 학생이 없는 경우도 있음을 알 수 있습니다.

[ ISA 관계 ]
그리고 우리가 자바의 다형성 중 상속에서 배웠듯이 사람은 학생이 될 수 있고, 어떤 학생은 휴학생, 재학생, 졸업생으로 나뉘어 질 수 있습니다. 이런 관계에서 결국 학생 IS A 휴학생 or 재학생 or 졸업생 과 같은 관계가 성립하는데, 이런 관계를 ISA관계라고 하고 아래와 같이 역삼각형으로 표현할 수 있습니다.
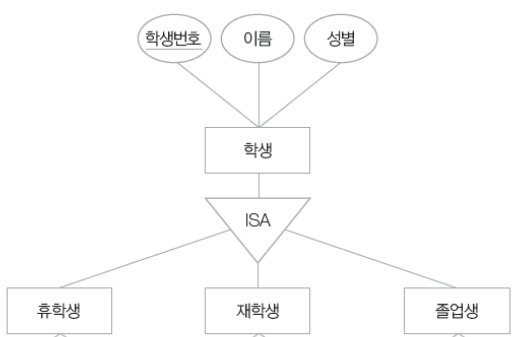
[ 참여 제약 조건 ]
개체 집합 내에서 모든 개체가 참여를 할 수도 있지만 그렇지 않은 경우도 있습니다. 그래서 우리는 모든 개체의 참여 유무에 따라 전체 참여와 구분 참여로 이를 구분합니다. 전체참여는 관계에 개체 집합의 모든 개체가, 부분 참여는 일부의 개체만 참여하는 것입니다. 즉, 전체참여는 (최솟값, 최댓값)에서 최솟값이 1 이상으로 모두 참여한다는 것이고, 부분참여는 최솟값이 0 이상으로 참여를 하지 않는 개체가 있을 수 있다는 의미입니다. 학생이 강좌를 수강하는 관계에서 모든 강좌는 반드시 수강에 포함되어야 하지만 학생은 수강을 하지 않을 수 있으므로 아래의 그림과 같이 표현할 수 있습니다.
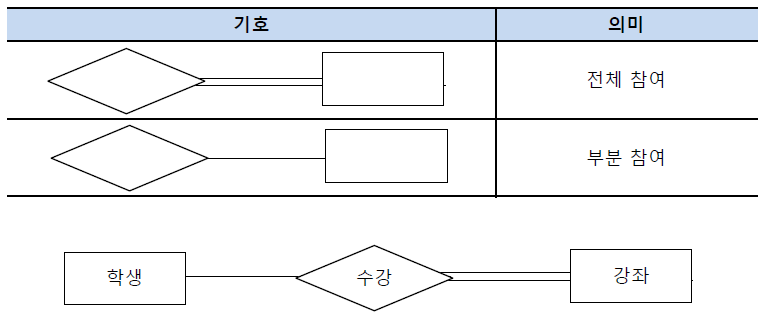
관계에서 각각의 개체는 어떠한 역할을 담당할 수 있기에, 그 역할을 아래와 같이 다이어그램에 표시해주기도 합니다.

순환적 관계는 하나의 개체 타입이 동일한 개체 타입과 순환적으로 관계를 가지는 형태를 의미합니다. 1진 관계에서 순환적 관계가 표현될 수 있는데, 어떤 학생은 멘토링이라는 관계에서 멘토가 될 수도 있고, 멘티가 될 수도 있습니다.

[ 약한 개체 타입과 식별자 ]
약한 개체 타입(Weak Entity Type)이란 상위 개체 타입이 결정되지 않으면 개별 개체를 식별할 수 없는 종속적인 개체타입을 의미합니다. 약한 개체 타입은 독립적인 키로는 존재할 수 없지만 상위 개체 타입의 키와 결합하여 약한 개체타입의 개별 개체를 고유하게 식별하는 속성을 식별자(Discriminator) 혹은 부분키(Partial Key)라고 합니다.
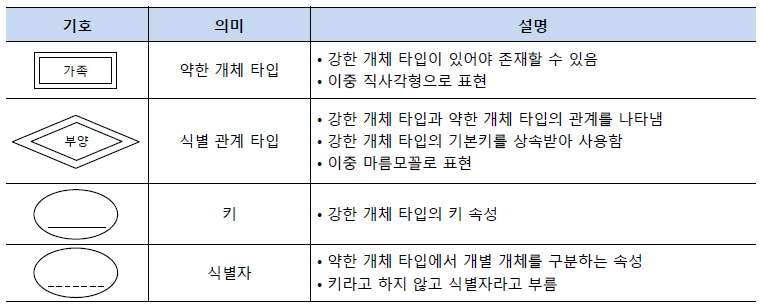
예를 들어 가족과 직원이라는 두 개의 개체가 부양이라는 관계를 맺고 있다고 합시다. 직원에는 직원번호, 이름, 직책이라는 속성들이 있고 직원번호가 직원의 고유키 입니다. 그런데 그 직원이 부양하는 가족이 있다고 할 때 직원이 없으면 부양가족도 존재할 수 없으므로 가족은 약한개체가 됩니다. 또한 부양가족의 이름이라는 속성은 직원의 직원번호와 결합하여 약한 개체 타입을 식별할 수 있으므로 식별자가 됩니다.

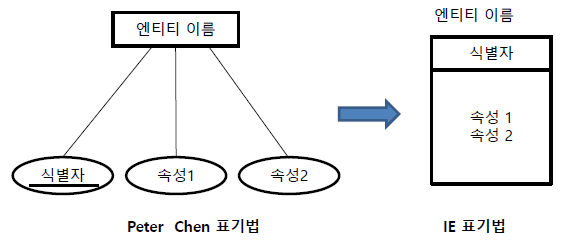
[ IE 표기법 ]
IE(Information Engineering)표기법은 ER다이어그램을 더욱 축약하여 쉽게 표현하기위해 Erwin 등의 소프트웨어에서 사용됩니다. IE표기법에서 개체타입과 속성은 직사각형으로 표기됩니다.
그리고 개체들 사이의 관계를 정의하는 방법은 아래의 표를 참고하면 됩니다. 개체가 강한 개체 타입을 갖는 경우(비 식별자적 관계)에는 점선, 약한 개체 타입(식별자적 관계)을 갖는 경우에는 실선으로 표시합니다. N쪽의 관계를 표현하기 위해서는 새발을 그려줍니다. o을 그려주는 것은 최소 참여가 0인 경우 즉 최소참여이고, |을 그려주는 것은 최소 참여가 1인 경우 즉 필수 참여인 경우입니다.
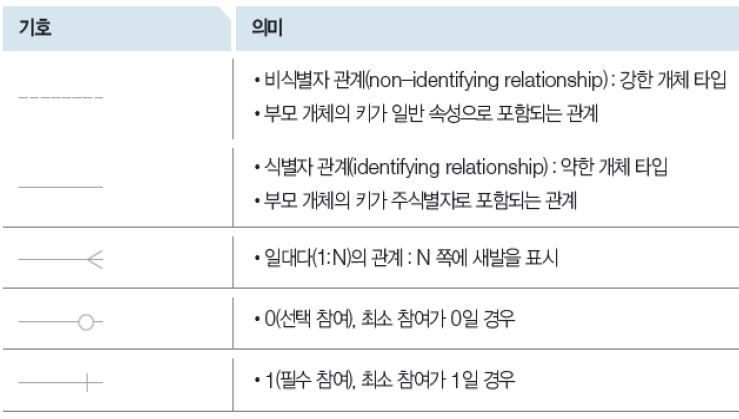
직원이 특정 부서에 소속되어 있는 경우 그리고 직원이 부양가족이 있는 경우에 대한 ER다이어그램을 IE 표기법을 나타내면 다음과 같습니다. 직원은 반드시 부서에 소속되어야 하므로 비식별자적 관계 즉, 점선으로 이어져있어야 하며 부서에 직원이 없을 수도 있으므로 부서에 대응하는 직원에 o 표시를 넣어주고, 모든 직원은 부서에 포함되어야 하므로 | 을 그려줍니다. 그리고 직원은 부양가족이 있을 수도 있고 없을 수도 있으므로 대응하는 부양가족의 표시에 o를 넣어주지만 부양가족은 자신들을 부양해주는 사람(직원)이 반드시 있어야 하므로 대응하는 직원의 표시에 |를 넣어줍니다. 또한 부양가족은 직원이 없이 부양가족의 이름만으로는 식별이 불가능하므로 (직원번호, 이름)을 식별자로 사용하며 실선으로 표기합니다.
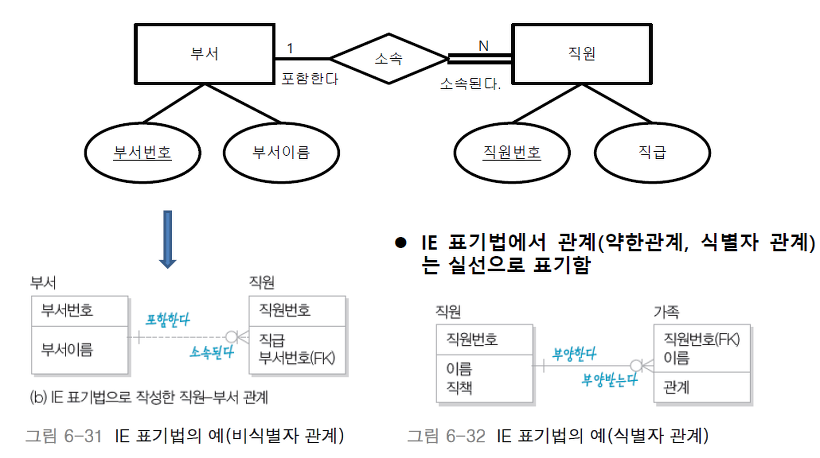
출처 : (mangkyu.tistory.com/27)
7. 정규화(Normalization)
1. 이상현상(Anomly)
[ 이상현상의 개념 ]
-
삭제 이상: 튜플 삭제 시 같이 저장된 다른 정보까지 연쇄적으로 삭제되는 현상
-
삽입 이상: 튜플 삽입 시 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
-
수정 이상: 튜플 수정 시 중복된 데이터의 일부만 수정되어 일어나는 데이터 불일치 현상
삭제 이상(Deletion Anomly)란 튜플을 삭제할 때 저장되어있는 다른 정보도 삭제되어 연쇄 삭제(Triggered Deletion)의 문제가 발생하는 경우를 의미합니다. 아래의 그림에서 장미란이라는 학생의 정보를 지울 경우 강의실 103도 같이 사라지게 되어 다른 튜플들이 강의실 103을 사용하지 못하는 경우에 발생한다. 삽입 이상(Insertion Anomly)란 튜플을 삽입하는 경우에 해당하는 정보가 없어 NULL을 넣는 현상입니다. 수정 이상(Update Anomly)란 어떤 값을 참조하는 튜플의 값을 수정할 때 같은 데이터를 참조하는 다른 튜플과 데이터가 달라지는 현상입니다. 예를 들어 아래의 박지성이라는 학생과 김연아라는 학생이 같은 데이터베이스라는 수업을 강의실 110호 에서 수강하고 있습니다. 그런데 두 강의는 독립적으로 입력된 데이터이기 때문에 박지성 학생에서 강의실을 201호로 변경하여도 김연아 학생은 110호로 데이터가 그대로 유지되고, 같은 데이터베이스 수업임에도 불구하고 강의실이 달라지는 현상이 발생합니다.
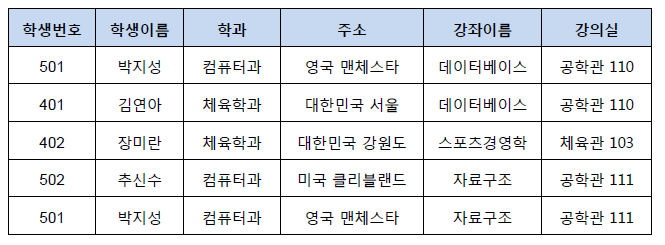
이러한 이상현상은 서로 공유하는 데이터임에도 불구하고 각자의 튜플에 독립적으로 존재하기 때문에 발생합니다. 그러므로 테이블을 분리하여 그 테이블을 통해 강의 제목이나 강의실을 참고하게끔 한다면 이상현상들을 해결할 수 있습니다.
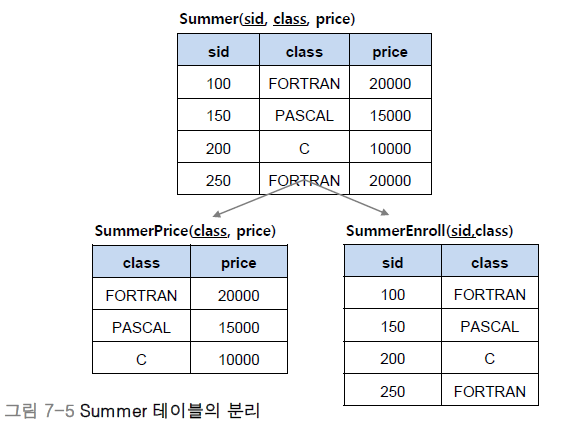
2. 함수 종속성(Functional Dependency)
[ 함수 종속성이란? ]
-
어떤 속성 A의 값을 알면 다른 속성 B의 값이 유일하게 정해지는 관계를 종속성이라 함
-
A->B로 표기하며 A를 B의 결정자라고 함
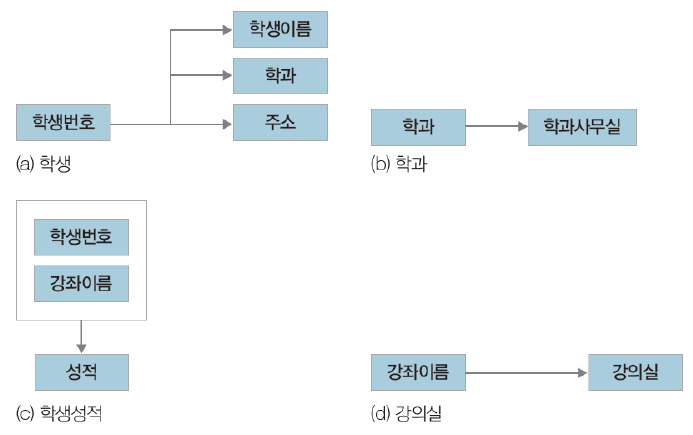
아래의 그림과 같은 학생 수강 성적 릴레이션이 있다고 가정합시다. 우리는 학생과 수강 그리고 성적의 속성에는 의존성이 존재한다고 표현합니다. 여기서 말하는 의존성이란 501이라는 학생번호를 보면 학생이름이 박지성으로 정해지는 관계를 의미하며, 정리하면 속성 A의 값을 알면 다른 속성 B의 값이 유일하게 정해지는 의존관계를 속성 B는 속성 A에 종속한다.(Dependent) 또는 속성 A는 속성 B를 결정한다(Determine)라고 합니다. 학생번호->학생이름 처럼 A->B로 표현하며 A가 B를 결정한다고 하여 A를 B의 결정자라고 합니다. 그 외에도 아래의 그림에는 학과 -> 학과사무실, 강좌이름 -> 강의실과 같은 종속관계가 있습니다. 종속하지 않는 관계로는 학과 -> 학생번호, 학생이름 -> 강좌이름이 있습니다. 학생이름 -> 학과는 종속하는 것처럼 보이지만 동명이인의 학생이 있는 경우 그 학생의 이름은 학과를 결정하지 못하므로 종속의 관계가 아닙니다.

[ 함수 종속성 다이어그램 ]
-
릴레이션의 속성: 직사각형
-
속성 간의 함수 종속성: 화살표
-
복합 속성: 직사각형으로 묶어서 그림
함수 종속성 다이어그램(Functional Dependency Diagram)은 함수 종속성을 나타내는 표기법입니다. 학생이름, 학과, 주소 등과 같은 릴레이션의 속성은 직사각형으로 표기합니다. 그리고 두 속성이 종속적인 관계를 가질 때 예를 들면 학생번호가 학생이름을 결정하는 관계를 가질 때는 화살표를 이용하여 종속성을 표현합니다. 또한 복합속성의 경우에는 그 속성들을 묶어 하나의 직사각형으로 표시해줍니다. 예를 들어 학생번호와 강좌이름을 확인하면 성적을 확인할 수 있으므로 학생번호와 강좌이름을 큰 직사각형으로 묶어 복합 속성으로 두고 성적에 화살표 연결을 해줍니다.

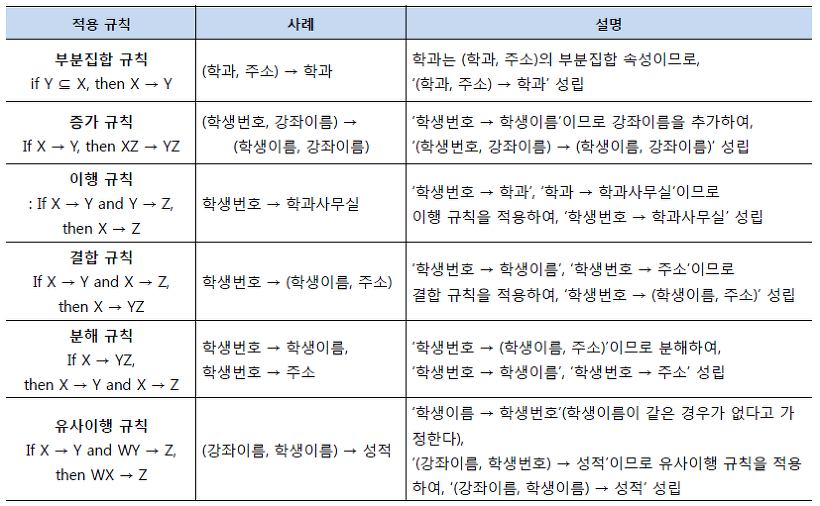
[ 함수 종속성 규칙 ]
-
부분집합 규칙: If Y ⊆ X, then X -> Y
-
증가 규칙 : If X -> Y then XZ -> YZ
-
이행 규칙 : If X -> Y and Y -> Z then, X -> Z
-
결합 규칙 : If X -> Y and X -> Z then, X -> YZ
-
분해 규칙 : If X -> YZ, then X -> Y and X -> Z
-
유사이행 규칙: If X -> Y and WY -> Z, then WX -> Z
[ 릴레이션과 기본키 ]
-
관계(Relationship)란 개체 사이의 연관성을 나타내는 개념이다.
-
관계 타입(Relationhip Type)이란 개체 타입과 개체 타입 간의 연결 가능한 관계를 정의한 것이다.
-
관계 집합(Relationship set)은 관계로 연결된 집합을 의미한다.
릴레이션의 함수 종속성을 파악하기 위해서는 우선 기본키를 찾아야 합니다. 기본키가 함수의 종속성에서 어떤 역할을 하는지 알면 이상 현상을 제거하는 정규화 과정을 쉽게 이해할 수 있습니다. 여기서 기본키는 한 릴레이션의 다른 속성들을 모두 결정할 수 있어야 합니다. 아래와 같은 그림에서 우리는 이름을 기본키로 사용하여 어디과인지, 어디에 사는지, 어떤 학점을 받았는지 알 수 있으므로 이름이라는 속성이 기본키가 된다고 분석할 수 있습니다.
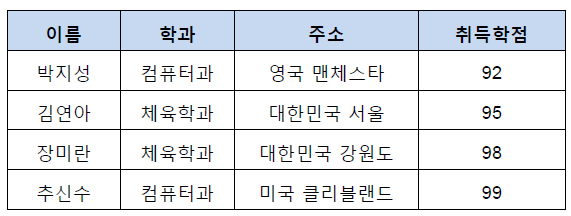
[ 이상현상과 결정자 ]
이해하셨다 시피 이상현상은 한 개의 릴레이션에 두 개 이상의 속성이 포함되어 있고 기본키가 아닌 속성이 결정자일 때 발생합니다. 위의 학생수강성적 릴레이션의 경우 기본키를 지닌 학생 정보(학생번호, 학생이름, 주소, 학과)와 기본키가 아니지만 결정자적 성질을 지닌 강좌 정보(강좌이름, 강의실)가 한 릴레이션에 포함되어 이상현상이 나타난 것입니다. 그 외에도 학과, 학생 번호, 강좌 이름은 기본키가 아니면서 결정자이기 때문에 이상현상을 해결하기 위해 우리는 총 4개의 릴레이션으로 학생수강성적 릴레이션을 분해하면 됩니다.
3. 정규화(Normalization)
[ 정규화 ]
-
정규화: 이상현상이 발생하는 릴레이션을 분해하여 이상현상을 없애는 과정
-
이상현상이 있는 릴레이션은 이상현상을 일으키는 함수 종속성의 유형에 따라 등급을 구분가능
-
릴레이션은 정규형 개념으로 구분하며, 정규형이 높을수록 이상현상은 줄어듬.
정규화란 즉 이상현상이 존재하는 릴레이션을 분해하여 여러 개의 릴레이션을 생성하는 과정을 의미합니다. 릴레이션은 분해되는 정도에 따라 정규형 단계로 나누어지며 정규형이 높아질수록 이상현상은 줄어듭니다.
[ 제1 정규형 ]
제1 정규형은 릴레이션의 모든 속성 값이 원자값을 갖는 경우입니다. 예를 들어 고객 취미들(이름, 취미들)이라는 릴레이션에 (추신호, (영화, 음악))이라는 열이 있다고 가정하면 이 속성들이 각각 다른 열로 분해된 릴레이션을 제1 정규형이라 합니다.
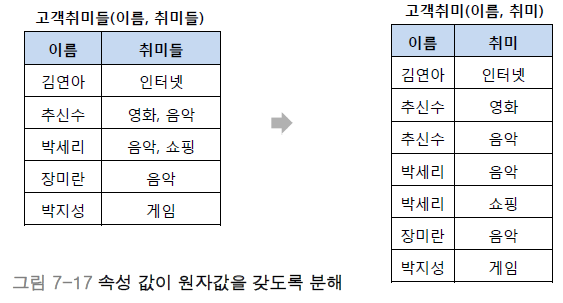
[ 제2 정규형 ]
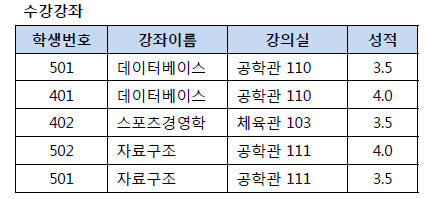
제2 정규형은 릴레이션이 제1 정규형을 만족하고, 기본키가 아닌 속성이 기본키에 완전 함수 종속일 때를 의미합니다. 여기서 완전 함수 종속이라는 말은 기본키로 묶인 복합키가 존재할 때 복합키(A,B,C)가 모여서 하나의 다른 값(X)를 결정하고 복합키의 부분집합이 결정자가 되면 안된다는 뜻입니다. 예를 들어 아래의 그림과 같이 수강강좌 릴레이션이 있고, (학생번호, 강좌이름)의 복합키를 가지고 있다고 가정합시다. 여기서 (501, 데이터베이스)가 모여서 성적이라는 하나의 값을 결정하지만, 강의실의 경우에는 (501, 데이터베이스) 중에서 강좌이름이 없어도 강의실을 결정 할 수 있습니다. 그러므로 이러한 관계를 부분 함수 종속이라고 하며 제2 정규형은 완전 함수 종속을 만족시켜야 하므로 강좌이름과 강의실을 분리하면 제2 정규형이 만들어 집니다.

[ 제3 정규형 ]
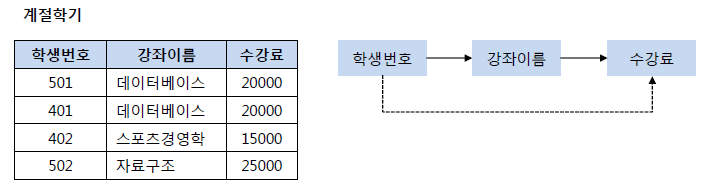
제3 정규형은 릴레이션 R이 제2 정규형을 만족하고 기본키가 아닌 속성이 기본키에 비이행적(Non-Transitive)으로 종속할 때(직접 종속)를 의미합니다. 여기서 이행적 종속이란, A->B, B->C가 성립할 때 A->C가 성립되는 함수 종속성을 의미합니다. 아래와 같은 계절학기 릴레이션에서 학생번호501의 강좌이름이 스포츠경영학으로 변경되면 수강료도 15000원으로 변경되어야 합니다. 그러므로 아래의 속성들을 독립적으로 만드는 것이 아니라 학생 번호로 학생이 수강하는 강좌이름을 찾게 하고 그 학생번호가 참조하는 강좌이름을 참조하여 수강료를 찾게하여 학생번호가 수강료를 참조할 수 있게 끔 만들면 제3 정규형이 됩니다.
[ BCNF 정규형 ]
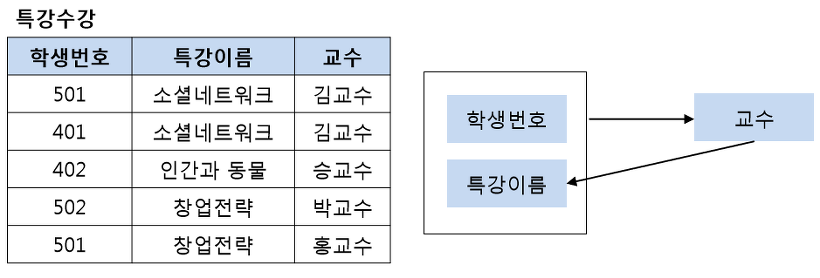
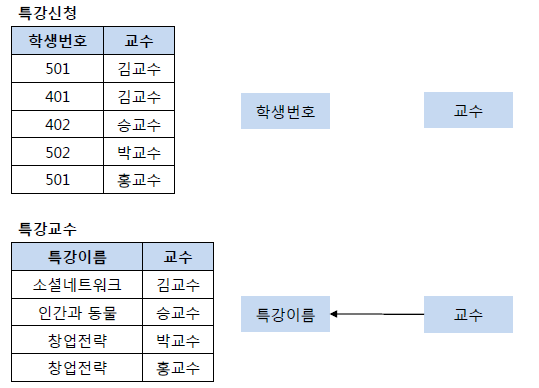
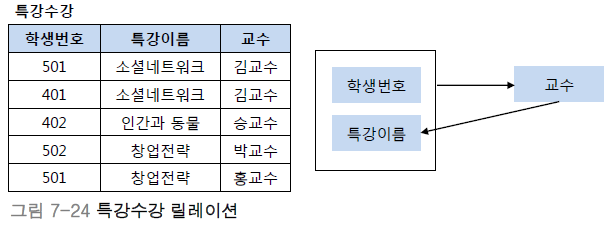
BCNF 정규형은 릴레이션 R에서 함수 종속성 X->Y가 성립할 때 모든 결정자 X가 후보키인 정규형입니다. 아래의 왼쪽 같은 그림에서 기본키는(학생번호, 특강이름) 이고 교수는 (학생번호, 특강이름)에 완전하게 함수적으로 종속하고 있습니다. 또한 교수 역시도 특강 이름을 결정하며 결정자의 역할을 하고 있습니다. 다음으로 모든 결정자 X가 후보키인지를 확인해야 합니다. (학생번호, 특강이름)은 기본키이므로 당연히 결정자이며 후보키입니다. 하지만 교수는 결정자이면서 후보키가 아니므로 아래의 왼쪽 테이블은 BCNF정규형이 아닙니다. BCNF정규형을 만족하기 위해서 왼쪽의 테이블을 오른쪽과 같이 분리해야 합니다.
[ 무손실 분해 ]
이상현상을 해결하기 위해서 우리는 릴레이션을 분해해야 한다는 것을 깨달았습니다. 하지만 하나의 릴레이션 R을 분해할 때 분해 후의 결과와 달라지면 문제가 발생하게 되므로 우리는 손실이 없이 릴레이션을 분해해야 합니다. 여기서 릴레이션 R을 R1과 R2로 분해할 때, R1▷◁R2를 만족하는 경우를 무손실 분해(Loseless-join decomposition)라고 합니다. 그리고 R1과 R2는 R1∩R2 -> R1 혹은 R1∩R2 -> R2 중 하나를 만족해야 합니다. 아래의 그림에서 교수 속성으로 분리한 후 다시 조인하면 원래의 릴레이션이 되지만 특강이름 속성을 사용하여 분해하는 경우는 창업전략의 교수님이 다르므로 원래의 릴레이션이 되지 않습니다. 그리므로 이 경우는 무손실 분해가 아닙니다.
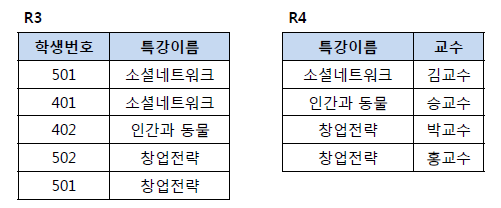
대부분의 릴레이션에서는 BCNF까지 정규화하면 실제적인 이상현상이 없어지기 때문에 BCNF 까지 정규화를 한다고 합니다.

출처 : (mangkyu.tistory.com/28)
8. 트랜잭션, 동시성 제어, 회복
1. 트랜잭션(Transaction)
[ 트랜잭션 ]
-
트랜잭션: DBMS에서 데이터를 다루는 논리적인 작업의 단위
-
DB에서 데이터를 다룰 때 장애가 일어난 경우 데이터를 복구하는 작업의 단위가 된다.
-
DB에서 여러 작업이 동시에 같은 데이터를 다룰 때가 이 작업을 서로 분리하는 단위가 된다.
-
트랜잭션은 전체가 수행되거나 또는 전혀 수행되지 않아야 한다.(All or Nothing)
우리가 데이터베이스에 삽입, 수정, 삭제 등의 작업을 할 때, 여러 개의 작업들을 하나의 트랜잭션으로 묶습니다. 즉, 트랜잭션은 DBMS에서 데이터를 다루는 논리적인 작업의 단위가 됩니다. 예를 들어 A계좌(박지성)에서 B계좌(김연아)로 돈을 이체하는 경우에 이 업무는 A에서 돈을 빼고 B에서 돈을 더하는 2가지의 Update문으로 나뉘게 됩니다. 그리고 이것들은 개별적으로 수행되는 것이 아니라 하나의 트랜잭션으로 묶이게 되며 하나의 트랜잭션이 실행될 때 이 2개의 SQL문이 연속적으로 실행됩니다. 그러므로 2개의 UPDATE문이 하나의 트랜잭션으로 묶여있다고 가정할 때 1개의 SQL만 실행되는 상황은 발생하지 않고 이를 All or Nothing 이라 합니다. 이어서 위의 계좌 이체 트랜잭션이 일어나는 세부 과정에 대해서 알아보도록 하겠습니다.
[ 트랜잭션 수행 과정 ]
-
A계좌의 값을 하드디스크(데이터베이스)에서 주기억장치 버퍼로 읽어온다.
-
B계좌의 값을 하드디스크(데이터베이스)에서 주기억장치 버퍼로 읽어온다.
-
A 계좌에서 10000원을 인출한 값을 저장한다.
-
B 계좌에서 10000원을 입금한 값을 저장한다.
-
A 계좌의 값을 주기억장치 버퍼에서 하드디스크(데이터베이스)에 기록한다.
-
B 계좌의 값을 주기억장치 버퍼에서 하드디스크(데이터베이스)에 기록한다.
위와 같은 트랜잭션의 수행 과정은 2가지 방법으로 나뉘어집니다. 먼저 2가지 방법을 알기 전에 커밋(Commit)이라는 개념을 알아야합니다. 여기서 Commit이란 트랜잭션의 수행이 완료됨을 트랜잭션 관리자에게 알려 주는 연산입니다. 2가지 방법은 Commit이 어느 위치에 들어가는지에 따라서 달라지는데, 4번까지 수행한 후 Commit을 할 수 있고, 6번까지 종료한 후 Commit을 할 수 있습니다. 여기서 DBMS는 사용자에게 빠른 응답을 위해 방법1을 택한다고 합니다.
방법1의 실제 동작: ①-②-③-④-Commit(부분 완료)-⑤-⑥-완료

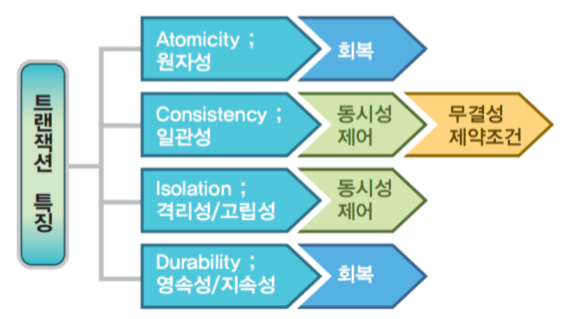
[ 트랜잭션의 ACID 성질 ]
-
원자성(Atomicity): 트랜잭션에 포함된 작업은 전부 수행되거나 전부 수행되지 않아야 한다.
-
일관성(Consistency): 트랜잭션을 수행하기 전이나 후나 데이터베이스는 항상 일관된 상태를 유지해야 한다.
-
고립성(Isolation): 수행 중인 트랜잭션에 다른 트랜잭션이 끼어들어 변경중인 데이터 값을 훼손하지 않아야한다.
-
지속성(Durability): 수행을 성공적으로 완료한 트랜잭션은 변경한 데이터를 영구히 저장해야 한다.
데이터베이스는 일반적인 프로그램과 다르게 4가지의 성질을 지니는데, 이를 ACID 성질이라고 합니다. 먼저 원자성이란 앞에서 보았던 All or Nothing의 성질으로 트랜잭션이 원자처럼 더 이상 쪼개지지 않는 하나의 프로그램 단위로 동작해야 한다는 의미합니다. 트랜잭션이 중간에 끊기면 이후에 해당 트랜잭션의 어디서부터 이어 수행되어야 하는지 모르기 때문에 원자성이라는 성질을 지니게 되었습니다. 또한 트랜잭션은 트랜잭션의 수행 전과 후에 일관된 상태를 유지해야 하고 이것을 일관성이라고 합니다. 예를 들어 어떤 테이블의 기본키와 같은 속성은 유지되어야 한다는 것 또는 A에서 B로 돈 이체를 할 때 A와 B계좌의 돈의 총합은 같아야한다는 것 등이 있습니다. 데이터베이스는 클라이언트들이 같은 데이터를 공유하는 것이 목적이므로 여러 트랜잭션이 동시에 수행되어야 합니다. 이때 트랜잭션은 상호 간의 존재를 모르고 독립적으로 수행되어야 한다는 것이 고립성입니다. 고립성을 격리성이라고 얘기하기도 하는데 이를 유지하기 위해서는 여러 트랜잭션이 동시에 접근하는 데이터에 대한 제어가 필요합니다. 마지막으로 트랜잭션은 지속성이라는 성질을 지녀야합니다. 지속성은 트랜잭션의 성공 결과 값은 장애발생 후에도 변함없이 보관되어야 한다는 것으로 트랜잭션이 정상적으로 완료(Commit)된 경우에는 버퍼의 내용을 하드디스크(데이터베이스)에 확실히 기록하여야 하며, 부분 완료(Partial Commit)된 경우에는 작업을 취소(Aborted)하여야 합니다. 즉, 정상적으로 완료 혹은 부분완료된 데이터는 DBMS가 책임지고 데이터베이스에 기록하는 성질이 지속성이며 영속성이라고 표현하기도 합니다.
[ 트랜잭션과 DBMS ]
-
DBMS는 원자성을 유지하기 위해 회복(복구)관리자 프로그램을 작동시킴.
-
DBMS는 일관성을 유지하기 위해 동시성 제어 알고리즘과 무결성 제약조건을 활용함.
-
DBMS는 고립성을 유지하기 위해 동시성 제어 알고리즘을 작동시킴.
-
DBMS는 지속성을 유지하기 위해 회복 관리자 프로그램을 이용함.
어떤 트랜잭션이 실행되다가 장애에 의해 부분 완료되는 상황은 원자성과 지속성이라는 속성에 위배됩니다. 그래서 DBMS는 이를 유지하기 위해 회복 관리자 프로그램을 이용하는데, 일부만 진행된 트랜잭션을 취소시켜 원자성을 유지할 뿐 아니라 값을 트랜잭션 이전의 상태로 복원시켜 지속성을 유지시켜줍니다. 또한 일관성과 고립성을 유지하기 위해서 값에 동시에 접근하지 않도록 하므로 동시성 제어(Locking)를 활용하여 이를 해결합니다. 파일 시스템과 같은 경우처럼 값이 덮어 씌워지는(Overwrite) 경우 일관성이 무너질 수 있고 그러한 경우는 고립성에 위배되는 경우이므로 Locking을 하여 이를 만족시킵니다. 여기에 더해 DBMS는 잘못된 값에 대한 입력이 오면 일관성이 무너질 수 있으므로 이를 유지시키기 위해 무결성 제약조건도 활용합니다.
[ 기타 개념들 ]
-
롤백(Rollback): 트랜잭션이 행한 모든 연산을 취소시키거나 트랜잭션을 재시작함.
-
DBMS는 일관성을 유지하기 위해 무결성 제약조건을 활용함.
-
DBMS는 고립성을 유지하기 위해 동시성 제어 알고리즘을 작동시킴.
-
DBMS는 지속성을 유지하기 위해 회복 관리자 프로그램을 이용함.
Rollback 연산은 트랜잭션의 실행 중에 장애가 발생한 경우에 수행됩니다. 장애가 발생한 경우는 데이터베이스에 일부만 반영되어 일관되지 못한 상태를 가질 수 있으므로 모두 취소하거나 트랜잭션을 재시작해야 합니다. 트랜잭션은 활동(Active), 부분완료(Partially Committed), 완료(Committed), 실패(Failed), 철회(Aborted)의 5가지 상태를 가지게 됩니다. 여기서 활동은 트랜잭션이 Begin_transaction으로 부터 실행을 시작하였거나 실행 중인 상태를 의미합니다. 부분 완료는 마지막 명령문을 실행시킨 직후의 상태를 의미하며 실패 또는 완료의 상태로 전이하게 됩니다. 실패는 트랜잭션의 실행 중에 장애나 오류가 발생하여 정상적인 실행을 더 이상 할 수 없는 상태이며 Rollback 연산을 수행한 상태인 철회 상태로 전이하게 됩니다. 위에서 Rollback에 의해 트랜잭션이 재시작 되거나 강제종료 되는 경우가 있다고 하였는데, 철회의 원인이 트랜잭션 자체의 논리적인 오류가 아닌 경우에는 재시작되며 트랜잭션 철회의 원인이 트랜잭션 내부의 논리적인 오류에 의해 오류를 수정해야 하는 상황이거나 얻고자 하는 데이터가 데이터베이스에 존재하지 않는 경우에 강제 종료 됩니다.

2. 동시성 제어(Currency Control)
[ 동시성제어 ]
-
다중 사용자 환경에서 둘 이상의 트랜잭션이 동시에 수행될 때, 일관성을 해치지 않도록 트랜잭션의 데이터 접근 제어
-
다중 사용자 환경을 지원하는 DBMS의 경우, 반드시 지원해야 하는 기능
위에서 배운 고립성은 상호 간의 트랜잭션을 독립적으로 만들어 주었습니다. 그런데 2개 이상의 트랜잭션이 하나의 값에 접근하는 경우에는 어떻게 될까요? 2개의 트랜잭션이 모두 읽는 경우에는 문제가 발생하지 않지만, 1개의 트랜잭션은 쓰고 1개의 트랜잭션은 읽는 경우에 상황에 따라 오손 읽기, 반복불가능 읽기, 유령데이터 읽기 문제가 발생할 수 있으며, 2개의 트랜잭션이 모두 쓰기(Write) 시 무제어 병행 수행을 하는 경우에 갱신 손실, 모순성, 연쇄 복귀 등의 문제가 발생할 수 있습니다.

[ 갱신 손실(Lost Update) ]
-
하나의 트랜잭션이 갱신한 내용을 다른 트랜잭션이 덮어씀으로써 갱신이 무효화가 되는 것을 의미
-
두 개의 트랜잭션이 한 개의 데이터를 동시에 갱신(Update)할 때 발생
-
데이터베이스에서 절대 발생하면 안되는 현상
갱신 손실은 1장의 파일 시스템에서 발생했던 문제와 유사합니다. 하나의 값에 계속해서 덮어쓰기(Overwrite)하여 데이터의 갱신이 무효화 되는 현상입니다. 초기값 X = 1000이 있고, 트랜잭션 T1은 X +=300, 트랜잭션 T2는 X-=500 이라 할 때, 동시성 제어를 해주지 않으면 1000이라는 값이 T1에 의해 1300이 된 상태에서 T2가 아직 1300으로 Write 되기 전인 X=1000을 Read하여 1300-500이 아니라 1000-500이 수행되어 500을 갖게 되었고 T1과 T2가 순차적으로 값을 저장하여 덮어씌워지는 값의 손실을 갱신손실이라 합니다.

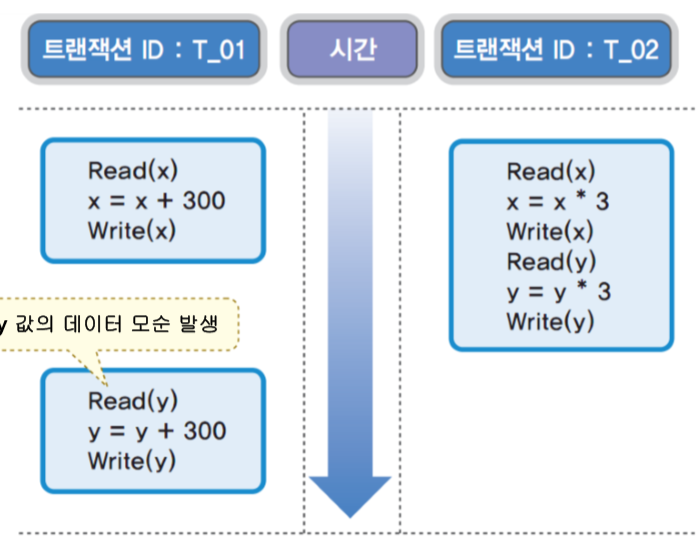
[ 모순성(Inconsistency) ]
-
다른 트랜잭션들이 해당 항목 값을 갱신하는 동안 한 트랜잭션이 두 개의 항목 값 중 어떤 것은 갱신되기 전의 값을 읽고 다른 것은 갱신된 후의 값을 읽게 되어 데이터의 불일치가 발생하는 상황
초기값 X=1500, Y=1000이 있고, 트랜잭션 T1은 X와 Y를 300 증가, 트랜잭션 T2는 X와 Y를 3배씩 증가시킨다고 합시다. 트랜잭션 T1이 수행될 때 X와 Y는 각각 1500과 1000이 읽혀야 합니다. T1이 수행되면서 X만을 1800으로 증가시키고 Write된 다음에 Y를 수행하는 것이 아닌 트랜잭션 T2가 수행된다고 합시다. 그러면 T2에 의해 X와 Y는 각각 5400과 3000이 되고 다시 T1의 Y가 Read를 해야하는 상황에서 1000이 아니라 3000이 읽히게 됩니다. 이렇게 어떤 값은 갱신 전의 값을, 다른 값은 갱신 후의 값을 읽어 데이터가 불일치하는 것을 모순성이라 합니다.
[ 연쇄 복귀(Cascading Rollback) ]
-
두 트랜잭션이 동일한 데이터 내용을 접근할 때 발생
-
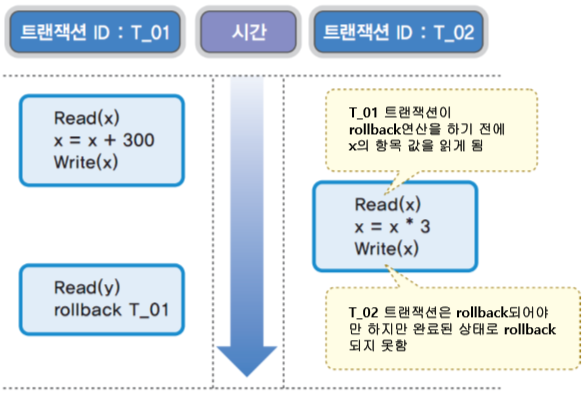
한 트랜잭션이 데이터를 갱신한 다음 실패하여 Rollback 연산을 수행하는 과정에서 갱신과 Rollback 연산을 실행하고 있는 사이에 해당 데이터를 읽어서 사용할 때 발생할 수 있는 문제
초기값 X=1500, Y=1000과 X를 300 증가시키고 Y를 200 감소시키는 트랜잭션 T1과 X항목을 3배 증가시키는 트랜잭션 T2가 있다고 합시다. T1이 X를 300 증가시키고 Write 하여 1800이 된 상황에서 T2 트랜잭션이 실행되어 X를 3배하여 Write한 후 종료되었다고 가정합시다. 그리고 T1이 이제 Rollback 연산을 하여 X를 1500으로 다시 돌려놓으려고 하는데 T2는 이미 해당 트랜잭션을 완료하여 종료되었으므로 롤백할 수가 없게 되버리는 문제가 발생합니다.
[ 트랜잭션 스케줄(Transaction Schedule) ]
-
직렬 스케줄(Serial Schedule)
-
비직렬 스케줄(Nonserial Schedule)
-
직렬 가능 스케줄(Serializable Schedule)
트랜잭션들은 삽입, 수정, 삭제 등과 같은 연산들로 이루어져있는데 여기서 트랜잭션 스케줄이란 그 연산들의 실행 순서를 의미합니다. 직렬 스케줄의 경우에는 트랜잭션의 연산을 모두 순차적으로 실행하는 유형을 의미합니다. 즉, 하나의 트랜잭션이 실행되면 해당 트랜잭션이 완료되어야 다른 트랜잭션이 실행될 수 있습니다. 비직렬 스케줄은 트랜잭션의 직렬 수행 순서와 상관없이 병행 수행하는 스케줄을 의미합니다. 그러므로 한 트랜잭션이 진행중인 상황에서 다른 트랜잭션이 실행될 수 있습니다. 마지막으로는 직렬가능 스케줄이 있는데 직렬 스케즐과 동등한 비직렬 스케줄을 의미합니다. 쉽게 설명하자면 서로 영향을 주지 않는 직렬 스케줄을 비직렬적으로 수행하겠다는 것입니다.

[ 직렬 가능 스케줄 ]
-
두 개의 트랜잭션이 Read 연산만을 수행할 것이라면, 상호 간섭이 발생되지 않으며 연산의 순서도 중요하지 않다.
-
두 개의 트랜잭션이 같은 데이터 항목에 접근하지 않는다면 상호 간섭이 발생되지 않으며 연산의 순서도 중요하지 않다.
-
T1이 X에 Write연산을 하고 T2가 X에 Read 또는 Write 연산을 한다면 실행 순서는 중요하다.
[ 락(Lock) ]
-
로킹(Locking)기법: 트랜잭션들이 동일한 데이터 항목에 대해 임의적인 병행 접근을 하지 못하도록 제어하는 것
-
트랜잭션 T가 데이터 항목 X에 대해 Read(X) or Write(X)연산을 수행하려면 반드시 lock(X) 연산을 해주어야 함
-
트랜잭션 T가 실행한 lock(X)에 대해서는 해당 트랜잭션이 종료되기 전에 반드시 unlock(x)연산을 해주어야 함
-
트랜잭션 T는 다른 트랜잭션에 의해 이미 lock이 걸려 있는 X에 대해 다시 lock(X)를 수행시키지 못한다.
-
트랜잭션 T가 X에 lock을 걸지 않았다면, unlock(X)를 수행시키지 못한다.
즉 여러 개의 트랜잭션들이 하나의 데이터로 동시에 접근하려고 할 때 이를 제어해주는 도구가 바로 Lock이다. 락은 트랜잭션이 읽기를 할 때 사용하는 공유락(LS, Shared Lock)과 읽고 쓰기를 할 때 사용하는 배타락(LX, Exclusive Lock)으로 나뉩니다. 트랜잭션 T가 데이터 항목 X에 대하여 Shared-Lock을 설정할 경우, 트랜잭션 T는 해당 데이터 항목에 대해서 읽을 수 있지만 기록할 수 없습니다. 그리고 Read는 서로 영향을 주지 않으므로 다른 트랜잭션도 Shared-Lock이 설정된 X에 대해서 Shared-Lock을 동시에 설정할 수 있습니다. 트랜잭션 T가 데이터 항목 X에 대하여 Exclusive-Lock을 설정할 경우, 트랜잭션 T는 해당 데이터 항목에 대해서 읽을 수도 있고, 기록할 수도 있습니다. Write는 영향을 주는 작업이므로 다른 트랜잭션은 Exclusive-Lock을 설정한 데이터 항목 X에 대해서 어떠한 lock도 설정할 수 없습니다.
[ 공유락과 베타락을 사용하는 규칙 ]
-
데이터에 락이 걸려있지 않으면 트랜잭션은 데이터에 락을 걸 수 있다.
-
트랜잭션이 데이터 X를 읽기만 할 경우 LS(X)를 요청하고, 읽거나 쓸 경우 LX(X)를 요청한다.
-
다른 트랜잭션이 데이터에 LS(X)를 걸어둔 경우, LS(X)의요청은 허용하고 LX(X)는 허용하지 않는다.
-
다른 트랜잭션이 데이터에 LX(X)를 걸어둔 경우, LS(X)와 LX(X) 모두 허용하지 않는다.
-
트랜잭션이 락을 허용받지 못하면 대기 상태가 된다.
[ 2단계 락킹 ]
-
로킹 단위: 로킹 기법에서 사용하는 lock 연산의 대상
-
2단계 로킹 규약: 락을 걸고 해제하는 시점에 제한을 두지 않으면 두 개의 트랜잭션이 동시에 실행될 때 데이터의 일관성이 깨질 수 있어서 로킹 단계를 2개로 구분하여 이를 방지하는 방법
-
확장 단계(Growing Phase): 트랜잭션은 새로운 lock 연산만 할 수 있고, unlock 연산은 할 수 없는 단계
-
축소 단계(Shrinking Phase): 트랜잭션은 unlock 연산만 실행할 수 있고, lock 연산은 실행할 수 없는 단계
로킹단위가 속성->튜플->릴레이션->데이터베이스로 커질수록 구현이 용이하고 록의 수가 적어지며 제어가 간단하지만 병행성이 떨어지는 반면 로킹단위가 작을수록 구현이 복잡하고 로크의 수가 많고 제어 기법이 복잡하여도 병행성을 높일 수 있습니다. 2단계 로킹 규약(2PLP: Two-Phase Locking Protocol)은 트랜잭션들이 lock하는 시간과 unlock을 하는 시간을 구분하여 수행하도록 하는 것입니다. 2단계 로킹 규약을 사용하지 않으면 아래의 그림과 같이 일관성이 위배되는 문제가 발생할 수 있습니다. 그래서 임의의 시간에 lock 또는 unlock을 하는 것이 아니라 확장 단계와 축소 단계를 두어 이를 해결해줍니다. 2PLP는 직렬 가능성을 보장할 수 있는 규약으로 가장 많이 사용되지만 교착상태가 발생할 가능성이 있지만 교착상태(데드락, Deadlock)에 빠질 수 있으므로 이를 해결해주어야 합니다.

[ 데드락(Deadlock) ]
-
데드락(Deadlock): 두 개 이상의 트랜잭션이 각각 자신의 데이터에 대하여 락을 획득하고 상대방 데이터에 대하여 락을 요청하면 무한 대기 상태에 빠질 수 있는 현상
-
데드락은 교착상태라고도 한다.
데이터베이스의 데드락과 운영체제의 데드락은 상당히 비슷합니다. 위의 정의를 풀어 설명하면 공통된 자원을 이용하기 위해 여러 개의 트랜잭션이 서로 lock을 걸어주다가 무한 대기 상태에 빠지는 것을 데드락이라 합니다. 예를 들어 먼저 T1에서 A에 대해 락을 걸고 T2에서 B에 대해 락을 걸었다고 합시다. 그리고 나서 T1에서 B에 대해 락을 걸고 T2가 A에 대해 락을 건다면 T1과 T2는 서로 A, B에 대한 락을 유지하며 무한루프에 빠지게 됩니다. 일반적으로 데드락이 발생하면 DBMS가 T1 혹은 T2 중 하나를 강제로 중지시켜 한 트랜잭션은 정상적으로 실행되며 중지된 트랜잭션에서 변경한 데이터는 원래 상태로 되돌려 놓습니다.

3. 트랜잭션 고립 수준
[ 오손읽기(Dirty Read) ]
-
읽기 작업을 하는 트랜잭션 1이 쓰기 작업을 하는 트랜잭션2가 작업한 중간 데이터를 읽기 때문에 발생하는 문제
-
작업중인 트랜잭션 2가 작업을 Rollback한 경우 트랜잭션 1은 무효가 된 데이터를 읽게 되고 잘못된 결과를 도출한다.
아래의 그림과 같이 T1이 T2가 Rollback되기 전의 데이터를 읽었고, T2가 Rollback이 되면 T1이 의미가 없는 값을 갖게 되므로 문제가 발생합니다. 그리고 이러한 무효가 된 데이터를 읽게되어 발생하는 문제를 오손읽기(Dirty Read)라고 합니다.

[ 반복불가능 읽기(Non-repeatable Read) ]
-
트랜잭션 1이 데이터를 읽고 트랜잭션 2가 데이터를 쓰고(Update) 르랜잭션 1이 다시 한번 데이터를 읽을 때 생기는 문제
-
트랜잭션 1이 읽기 작업을 다시 한 번 반복할 경우 이전의 결과와 다른 결과가 나오는 현상
아래의 그림과 같이 T1이 먼저 값을 읽었고 T2가 값을 갱신(Update)하였다고 합시다. 그리고 T1이 다시 값을 읽으려고 하면 바로 전에 읽은 값이 달라지는데 이를 반복불가능 읽기라고 합니다.
[ 유령데이터 읽기(Phantom Read) ]
-
트랜잭션 1이 데이터를 읽고 트랜잭션 2가 데이터를 쓰고(Insert) 트랜잭션 1이 다시 한번 데이터를 읽을 때 생기는 문제
-
트랜잭션 1이 읽기 작업을 다시 한 번 반복할 경우 이전에 없던 데이터(유령 데이터)가 나타나는 현상
아래의 그림과 같이 T1이 먼저 값을 읽었고, T2가 값을 삽입(Insert)하였다고 합시다. 그리고 T1이 다시 값을 읽으려고 하면 바로 전에는 없었던 값이 읽히게 되는데 이를 유령데이터 읽기라고 합니다.
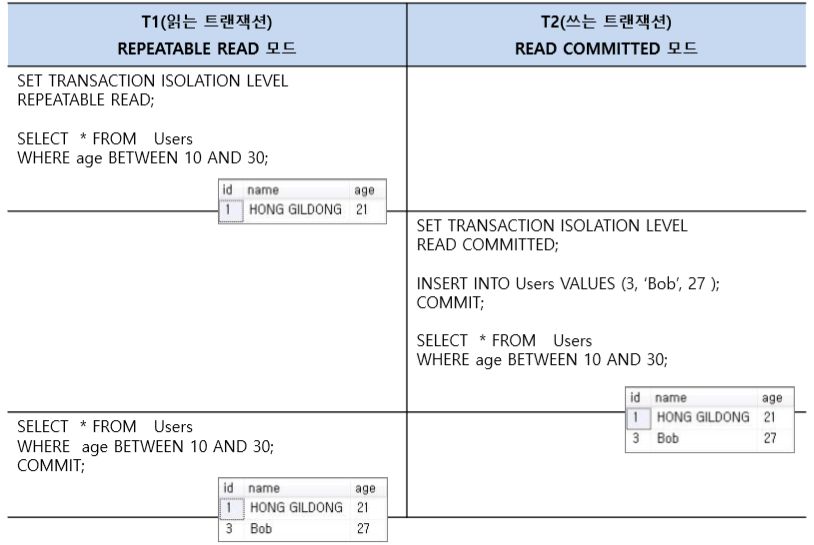
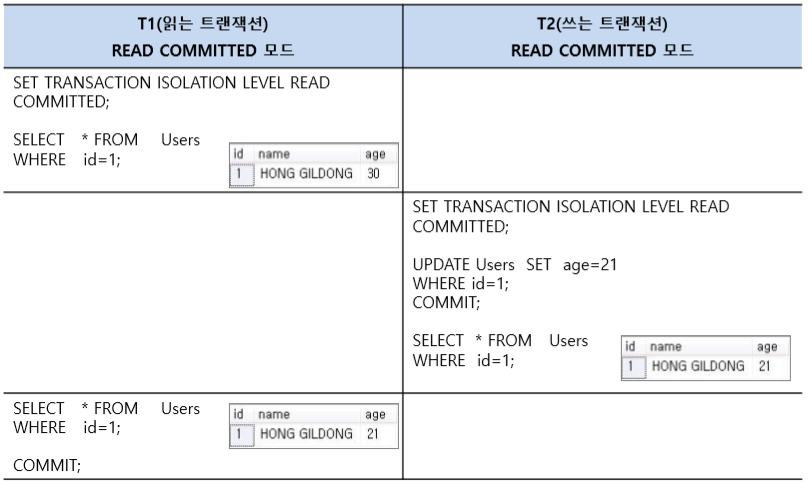
[ 트랜잭션 고립 수준 명령어(Transaction Isolation Level Instruction) ]
-
DBMS는 트랜잭션을 동시에 실행시키면서 락보다 좀 더 완화된 방법으로 문제를 해결하기 위해 제공하는 명령어
트랜잭션이 작업을 수행하다 보면 위의 오손 읽기, 반복불가능 읽기, 유령데이터 읽기와 같은 문제를 직면할 수 있습니다. 그래서 Lock보다는 완화된 방법으로 트랜잭션을 동시에 실행시키면서, 발생하는 문제를 해결하기 위해 DBMS가 제공하는 명령어가 바로 트랜잭션 고립 수준 명령어(Transaction Isolation Level Instruction)입니다. 여기에는 고립 수준을 나타내는 READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE과 같은 명령어들이 있습니다.

[ READ UNCOMMITTED ]
-
고립 수준이 Level 0으로 가장 낮은 명령어로, 자신의 데이터에 아무런 공유락을 걸지 않는다.
READ UNCOMMITTED는 자신의 데이터에 아무런 공유락도 걸지 않지만 배타락은 데이터의 갱신손실 문제 때문에 걸어주어야 합니다. 또한 다른 트랜잭션에 공유락과 배타락이 걸린 데이터를 대기하지 않고 읽습니다. SELECT 문을 수행하는 경우 해당 데이터에 Shared Lock이 걸리지 않는 Level입니다. 따라서, 어떤 사용자가 A라는 데이터를 B라는 데이터로 변경하는 동안 다른 사용자는 B라는 아직 완료되지 않은 데이터(오손 데이터) B를 읽을 수 있습니다.

[ READ COMMITTED ]
-
고립 수준이 Level 1인 명령어로, 오손 페이지의 참조를 피하기 위해 자신의 데이터를 읽는 동안 공유락을 걸지만 트랜잭션이 끝나기 전에라도 해지 가능하다.
다른 트랜잭션 데이터는 락 호환성 규칙에 따라 진행됩니다. SQL Server가 Default로 사용하는 Isolation Level으로 SELECT 문이 수행되는 동안에 Shared Lock이 걸리게됩니다. 그러므로 어떤 사용자가 A라는 데이터를 B라는 데이터로 변경하는 동안에 다른 사용자는 해당 데이터에 접근할 수 없습니다.

[ REPEATABLE READ ]
-
고립 수준이 Level 2인 명령어로, 자신의 데이터에 설정된 공유락과 배타락을 트랜잭션이 종료될 때까지 유지하여 다른 트랜잭션이 다신의 데이터를 갱신(Update)할 수 없도록 한다.
다른 트랜잭션 데이터는 락 호환성 규칙에 따라 진행됩니다. 다른 고립화 수준에 비해 데이터의 동시성(Concurrency)이 낮아 특별하지 않은 상황이라면 사용하지 않는 것이 좋습니다. 즉, 트랜잭션이 완료될 때까지 SELECT문이 사용하는 모든 데이터에 Shared Lock이 걸리므로 다른 사용자는 그 영역에 해당되는 데이터에 대한 수정이 불가능합니다. 예를 들어 SELECT number FROM A WHERE number BETWEEN 1 and 10을 수행하였고, 이 범위에 해당하는 number가 2 or 3이 있는 경우 다른 사용자가 number가 2 or 3인 행에 대한 UPDATE가 불가능하지만 나머지 범위에 대해서 행을 INSERT하는 것이 가능합니다.

[ SERIALIZABLE ]
-
고립 수준이 Level 3으로 가장 높은 명령어로, 실행 중인 트랜잭션은 다른 트랜잭션으로부터 완벽하게 분리된다.
데이터 집합에 범위를 지어 잠금을 설정할 수 있기 때문에 다른 사용자가 데이터를 변경(UPDATE) 또는 삽입(Insert)하려고 할 때 트랜잭션을 완벽하게 분리할 수 있습니다. 이 명령어는 가장 제한이 심하고 동시성도 낮습니다. 즉, SELECT 문이 사용하는 모든 데이터에 Shared Lock이 걸리므로 다른 사용자는 그 영역에 해당되는 데이터에 대한 수정(UPDATE) 및 입력(INSERT)가 불가능합니다. 앞의 Repeatable Read의 경우에는 1에서 10사이의 number에 대한 삽입이 가능하였지만 SERIALIZABLE은 SELECT의 대상이 되는 모든 테이블에 Shared Lock을 설정하는 것과 같아서 나머지 범위에 대한 INSERT가 불가능합니다.

4. 회복(Recovery)
[ 장애의 유형 ]
-
트랜잭션 장애: 트랜잭션의 실행 시 논리적인 오류로 발생할 수 있는 에러 상황
-
시스템 장애: H/W 시스템 자체에서 발생할 수 있는 에러 상황
-
미디어 장애: 디스크 자체의 손상으로 발생할 수 있는 에러 상황
트랜잭션 실행 시 발생할 수 있는 에러 상황의 원인으로는 트랜잭션 내에 잘못된 데이터 입력, 데이터의 부재, 오버플로우(Overflow), 자원의 한계 초과 요청, 어떤 수를 0으로 나누게 되는 연산 등이 있습니다. 시스템 장애는 하드웨어 자체에서 발생할 수 있는 에러로 하드웨어의 잘못된 작동으로 메인 메모리에 저장되어 있는 정보가 손실되거나 교착 상태의 발생으로 더 이상 트랜잭션 작업이 수행될 수 없는 상황에서 발생합니다. 마지막으로 미디어 장애는 디스크의 손상으로 발생할 수 있는 에러로 디스크 헤드 손상이나 고장으로 인해 저장장치 내의 정보가 일부 또는 전부 손상될 수 있는 상태입니다.

[ 회복(Recovery) ]
-
데이터베이스를 장애가 발생했던 이전의 상태로 복구시켜서 일관된 데이터베이스 상태를 만드는 것
데이터베이스를 갱신하는 과정에서 장애가 발생한 경우 회복절차를 수행하여 장애 발생 이전의 데이터베이스로 만드는 것을 회복이라고 합니다. 회복을 위한 데이터 복사본을 만드는 방법에는 덤프(Dump)를 이용하는 방법과 로그(Log)를 이용하는 방법 2가지가 있습니다. 덤프는 가장 기본적인 기법으로 일정 주기로 원본의 데이터베이스의 모든 내용을 다른 저장장치에 복사하는 것입니다. 로그는 변경 이전의 데이터베이스를 기준으로 변경 연산이 발생할 때 마다 로그 파일을 작성하여 기록하고, 회복할 때 로그에 적힌 내용을 사용하여 복원하는 방법입니다.

[ 로그파일(Log File) ]
-
트랜잭션이 반영한 모든 데이터의 변경사항을 데이터베이스에 기록하기 전에 미리 기록해두는 별도의 데이터베이스
-
안전한 하드디스크에 저장되며 전원과 관계없이 기록이 존재
-
로그의 구조: <트랜잭션 번호, 로그의 타입, 데이터 항목 이름, 수정 전 값, 수정 후 값>
-
로그의 타입: START, INSERT, UPDATE, DELETE, ABORT, COMMIT 등 트랜잭션의 연산 타입
로그(Log)란 트랜잭션이 데이터의 변경사항을 데이터베이스에 직접 기록하기 전에 미리 기록해두는 별도의 데이터베이스로 특정한 구조를 가지고 기록이 되며 장애 발생 시 복원을 위해서 사용됩니다. 실제로 아래와 같은 형식으로 로그가 기록됩니다. 또한 트랜잭션이 기록되는 정보들은 아래의 그림에서 참고할 수 있습니다.
<T1, START>
<T1, UPDATE, Customer(박지성).balance, 10000, 9000>
<T1, UPDATE, Customer(김연아).balance, 10000, 11000>
<T1, COMMIT>

[ 로그 파일을 이용한 회복 ]
-
데이터의 변경이 발생할 때 마다 생성되는 로그 파일을 이용하는 것
-
데이터의 변경 기록을 저장해 둔 로그 파일을 이용하면 시스템 장애도 복구 가능
DBMS는 트랜잭션이 종료되었는지 혹은 중단되었는지 여부를 판단하여 종료된 경우에는 종료를 확정하기 위하여 REDO(재실행)을 하고 중단된 경우에는 없던 일로 되돌리기 위해 UNDO(취소)를 진행합니다. REDO는 장애가 발생한 후 시스템을 다시 가동을 했을 때, 로그 파일에 트랜잭션의 시작(START)이 있고 종료(COMMIT)이 있는 경우 로그를 보면서 트랜잭션이 변경한 내용을 다시 기록하는 과정입니다. UNDO는 장애가 발생한 후 시스템을 재가동했을때, 로그 파일에 트랜잭션의 시작(START)만 있고 종료(COMMIT)이 없는 경우 완료하지 못했지만 버퍼의 변경 내용이 데이터베이스에 기록되어 있을 가능성이 있기 때문에 로그를 보면서 트랜잭션이 변경한 내용을 원상복구시키는 과정입니다. REDO의 경우에는 T1에 의해 변경된 모든 데이터 항목들을 로그 파일에 있는 새로운 값(New Value)으로 대체시켜야 하고 이를 T1의 첫 번째 로그 레코드 부터 진행합니다. 하지만 UNDO의 경우에는 T1에 의해 변경된 모든 데이터 항목들을 로그 파일에 있는 예전 값(Old Value)로 대체하여야 하고 장애가 발생한 마지막 로그 레코드부터 거꾸로 진행합니다.


트랜잭션이 시작하면 변경연산에 대해서 계속 로그 파일에만 기록을 하고 실제 데이터베이스에는 반영을 하지 않습니다. 그러다가 부분 완료까지 성공을 하면 로그 파일을 참조하여 실제 데이터베이스의 값을 변경시킵니다. 트랜잭션이 실패한 경우에는 연산이 로그파일에만 저장이 되어있고 데이터베이스에는 반영되어있지 않으므로 추가 작업이 필요 없지만 중간에 부분 완료를 거친 후에 트랜잭션 실패가 발생한다면, 데이터베이스에 일부 기록된 내용이 있을 수 있으므로 이러한 경우에는 UNDO를 해주어야 합니다. 아래의 그림에서 왼쪽은 트랜잭션이 성공한 경우이며 오른쪽은 트랜잭션이 실패한 경우에 해당합니다.
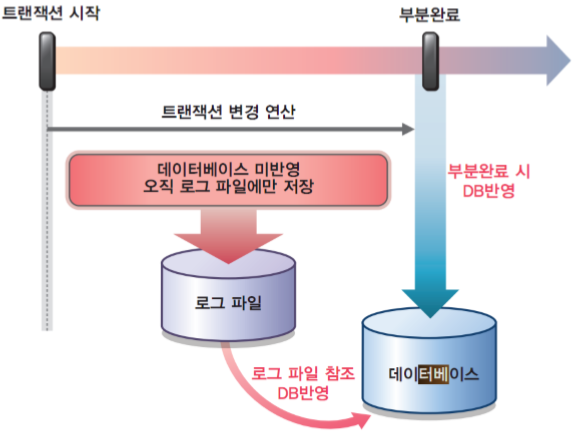
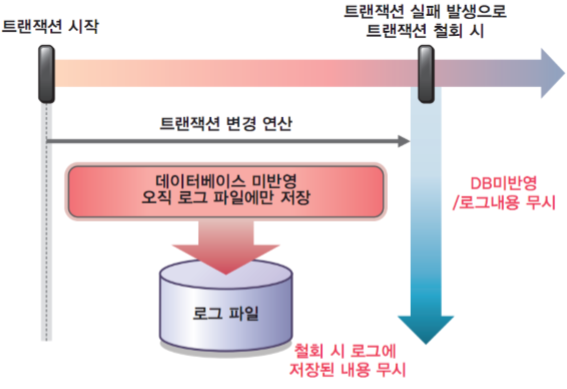
[ 로그 파일의 회복 방법 ]
-
즉시 갱신(Immediate Update): 갱신 데이터->로그, 버퍼->데이터베이스 작업이 부분완료 전에 동시에 진행될 수 있으며, 부분 완료가 되면 갱신 데이터는 로그에 기록이 끝난 상태
-
지연 갱신(Deferred Update): 갱신 데이터->로그가 끝난 후 부분 완료를 하고 버퍼->데이터베이스 작업이 진행되는 방법
즉시 갱신은 갱신된 데이터를 로그에 기록하는 작업과 버퍼의 데이터를 데이터베이스에 옮기는 작업이 동시에 진행될 수 있으며 부분완료가 된 경우는 로그에 기록이 끝난 상태인 반면에 지연 갱신은 갱신된 데이터를 로그에 작성하는 작업이 끝난 후에야 버퍼의 데이터를 데이터베이스로 옮기는 작업이 진행될 수 있습니다.
[ 체크포인트(CheckPoint, 검사점) ]
-
로그는 그대로 기록을 유지하면서, 회복 관리자가 정하는 일정한 시간 간격으로 검사 시점을 생성하는 것
-
회복 시 많은 양의 로그를 검색하고 갱신하는 시간을 줄이기 위함
-
체크포인트가 있으면 로그를 이용한 회복 기법은 좀 더 간단해짐
DBMS에서 회복을 할 때 처음부터 마지막 로그 기록까지 한번에 처리하려면 시간적으로 오래 걸릴 수 밖에 없습니다. 그러므로 특정 시간 마다 검사를 하여 문제가 없음을 확인하면 다음번 에러 발생 시 회복을 시작하는 시점을 앞으로 당길 수 있습니다. 그래서 체크 포인트 시점에는 다음과 같은 작업을 수행하게 됩니다. 먼저 주기억장치의 로그 레코드를 모두 하드디스크의 로그 파일에 저장합니다. 그리고 트랜잭션 수행 중에 변경된 버퍼 내의 내용을 하드디스크의 데이터베이스에 저장합니다. 그리고 나서 체크포인트를 로그 파일에 다음과 같이 표시합니다. <Checkpoint T_List>: T_list는 현재 수행 중인 트랜잭션의 리스트입니다.
-
체크포인트 이전에 [Commit] 기록이 있는 경우: 아무 작업이 필요 없다.
-
체크포인트 이후에 [Commit] 기록이 있는 경우: REDO(T)를 진행한다.
-
체크포인트 이후에 [Commit] 기록이 없는 경우: 즉시 갱신 방법 사용시 UNDO(T) 진행
체크포인트 이전에 Commit이 있는 경우는 로그에 체크포인트가 나타나는 시점은 이미 변경 내용이 데이터베이스에 모두 기록된 후이기 때문에 아무런 작업도 필요하지 않습니다. 체크포인트 이후에 Commit 기록이 있는 경우는 체크포인트 이후에 변경 내용이 데이터베이스에 반영되지 않았으므로 REDO를 진행합니다. 체크포인트 이후에 Commit 기록이 없고 즉시 갱신 방법을 사용한 경우는 갱신 데이터를 로그에 작성하는 과정과 버퍼의 내용을 데이터베이스에 기록하는 작업이 동시에 이루어지므로 버퍼의 내용이 데이터베이스에 반영됐을 수도 있기 때문에 원상복구 시켜야하므로 UNDO를 해야합니다. 하지만 체크포인트 이후에 Commit 기록이 없고 지연 갱신 방법을 사용한 경우는 갱신 데이터를 로그에 작성한 후 Commit을 시작해야 버퍼의 내용을 데이터베이스에 기록하는 작업이 이루어지므로 아무 작업도 해줄 필요가 없습니다.


출처 : (mangkyu.tistory.com/30)
'Develope_MySQL > 01_MySQL' 카테고리의 다른 글
| 이것이 MySQL이다 CH 9 인덱스 (0) | 2021.02.08 |
|---|---|
| 이것이 MySQL 이다 -Ch 8. (0) | 2021.02.08 |
| 이것이 MySQL이다. CH7. (0) | 2021.02.08 |
| 이것이 MySQL이다 CH4 데이터베이스 모델링 (0) | 2021.02.08 |
| 이것이 MySQL이다(Ch15) - 파이썬, 개발자를 위한 파이썬 (Ch10) (0) | 2021.02.08 |