
데이터 만능주의 에빠져 있다.
어떻게 하면 되는지는 알려주지 않고 개념적인 이야기만 하고 있다.
나오나 안나오냐가 아니라 내가 어떤 역량을 갖고 있느냐가 중요함


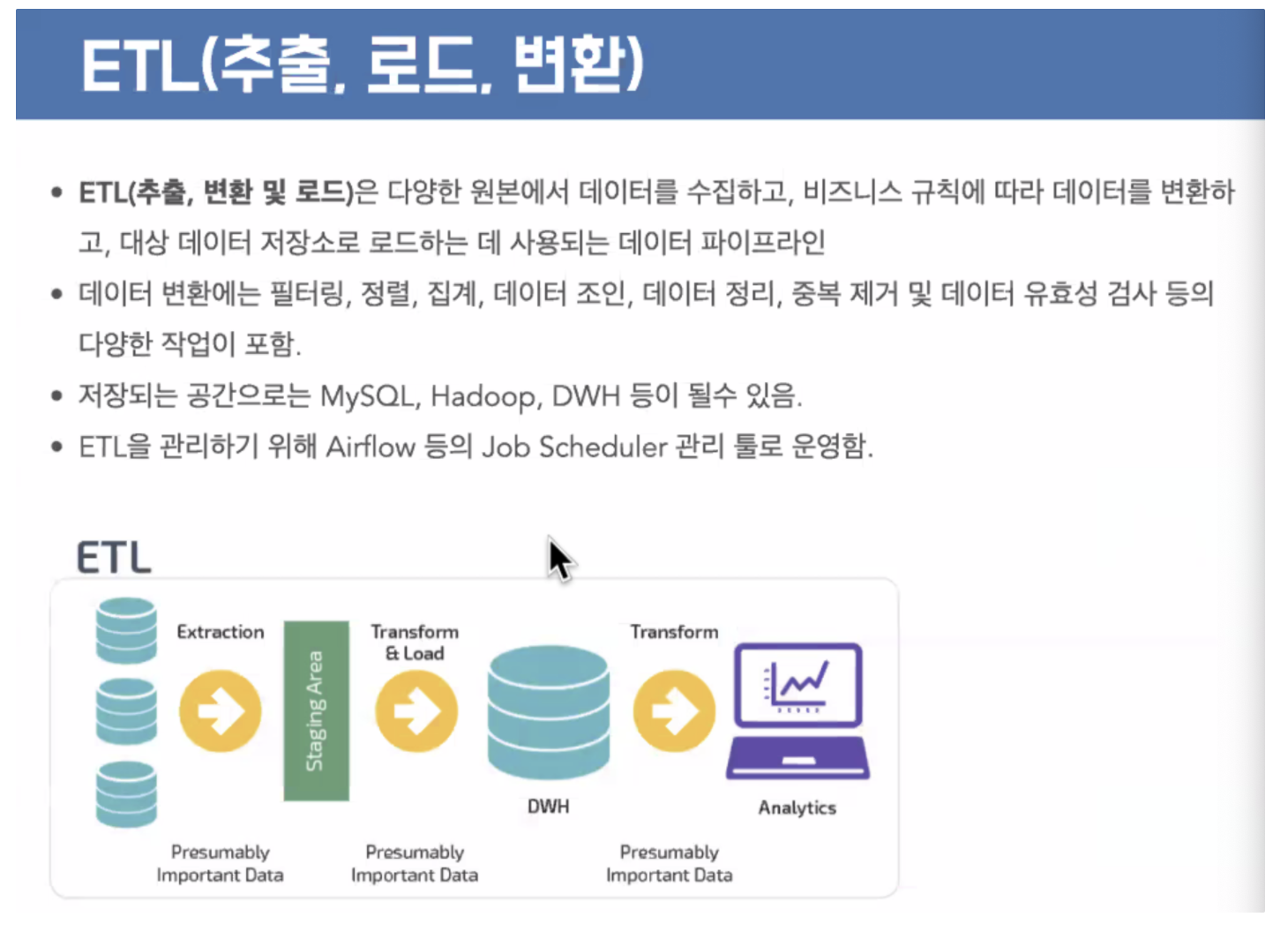
my sql 등으로 시작해서 하둡으로 확장

카프카 같은 수로를 만들게 된다. → 혈관 설계
댐이 있으면 저수지로


노이즈 제거, 가공, 디스플레이할 수 있게 차트를 함.
시각화가 없으면 → 엑셀 같은거 보면 의미가 없다.
시계열 / 유입량 / 증가량 → KPI → key matrix

위는 마이크로 소프트 / 아래는 AWS
2010년만 하더라도 정의되어 있지 않았는데
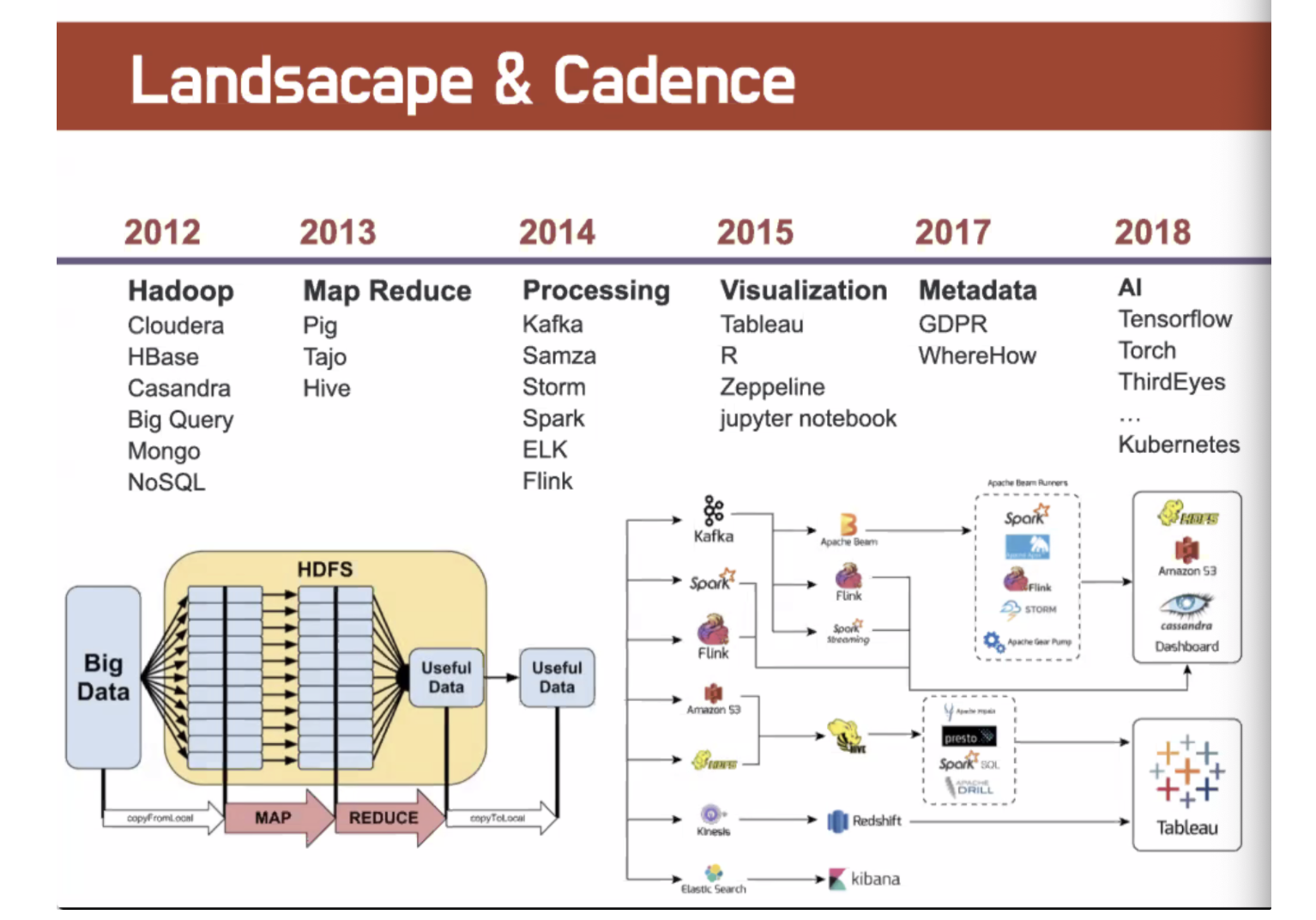
하둡의 발전 : 야후 → 에러가 많고, 일일히 들여다 봐줘야 한다. 하둡에 넣는 순간 넣고 빼기 아주 어렵다. 실리콘 밸리 기업들이 잘 안쓰려고 한다.
구글의 빅콜? → 하둡은 머리아프고 만능이 아니다.
Hbase, Facebook, 등이 기여 했다.
2013년부터 줄여나가야 한다. 요약하고 처리하기 위해 map reduce 등장
2014년부터 처리 단계 2015년 부터 데이터 모으고 처리하기 위해서 시각화가 중요해짐
2017년부터 GDPR → 데이터 정규화떄문에 요구됨 2018년부터 인공지능이 요구됨
왼쪽처럼 단순했다면 오른쪽처럼 클라우데라를 깔면 위 패키지를 쓸수가 있다. 발전 가능
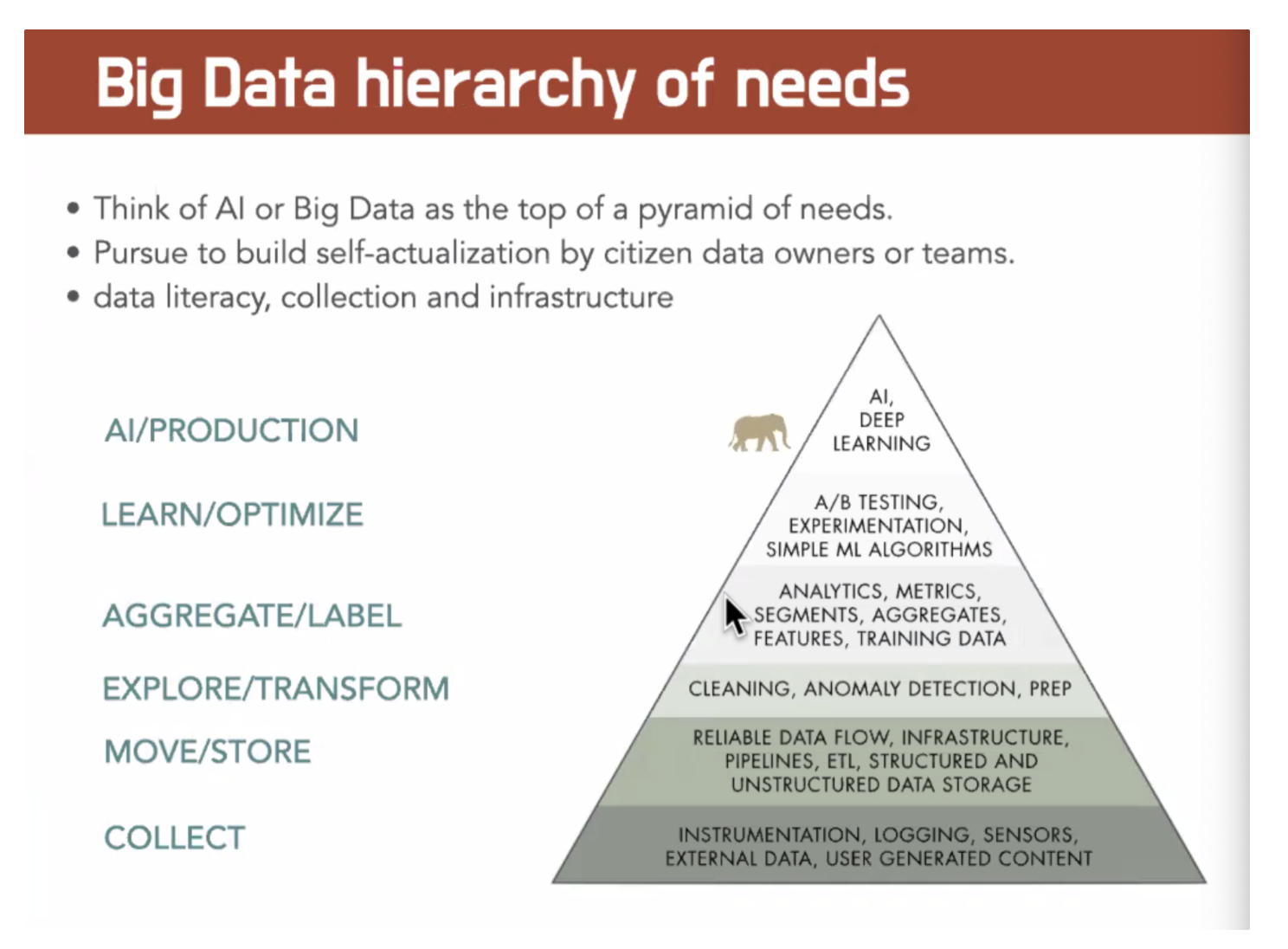
이 전체를 짜는 것이 시스템을 돌아가게 하고 모두가 연결되어야 한다.

데이터를 모으고 데이터 셋에 의해서 분류하고, 넘겨놓고, 데이터를 관리하고 가공하는데 있어서 매우 중요하다!! 보안사항도 중요하다

신발이라고 찾는다 ? 무슨 행동을 했는지를 알게 된다. 구글은 다 안다. 구글, 페이스북은 다 하고 있다. → 광고 캠페인 회사니까 바로 한다.

실시간 처리의 예시

데이터가 모든 것을 결정해주진 않지만, 데이터가 참고하게 해준다. 데이터 중심으로 결정한다!!
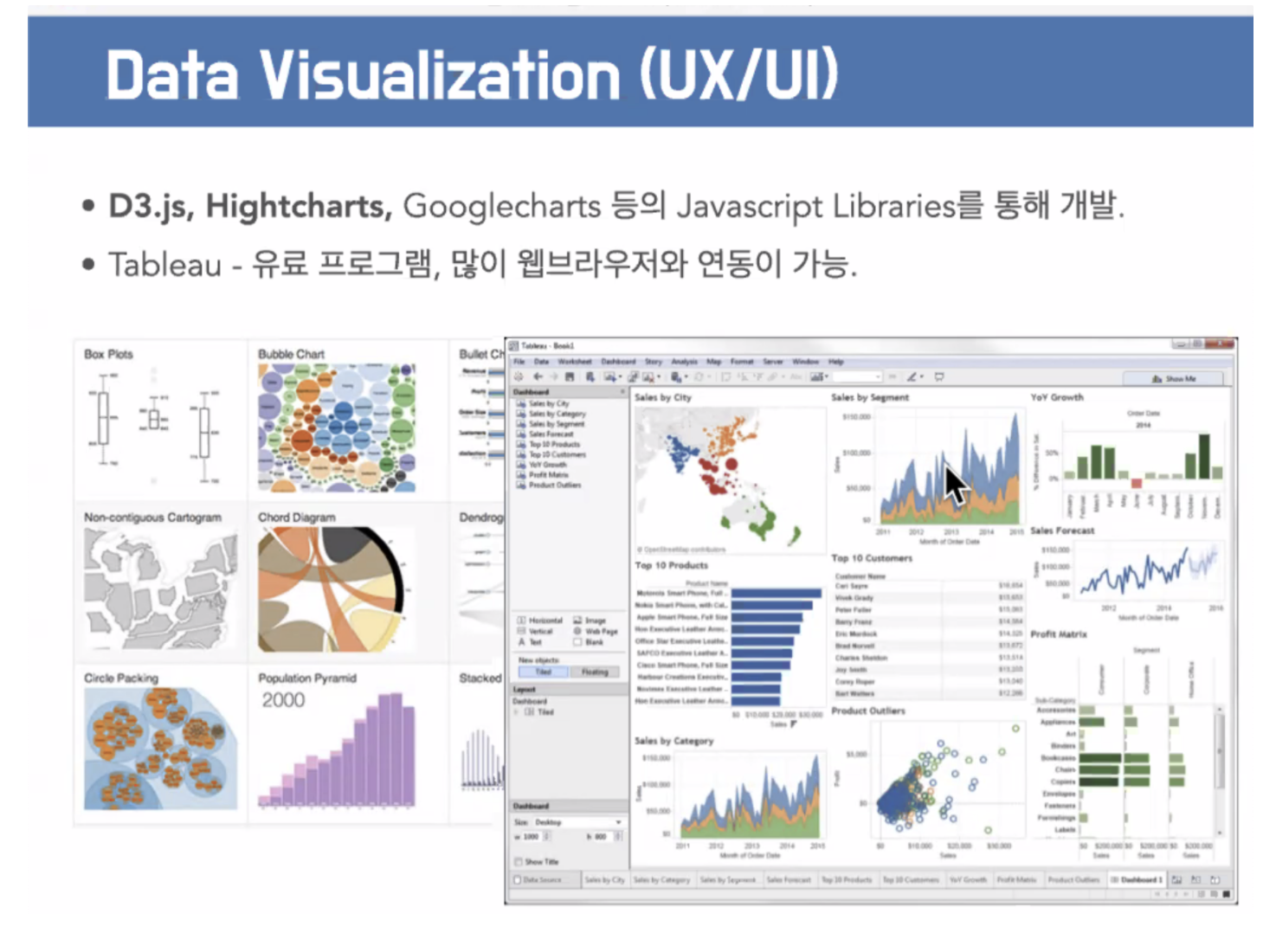


현업은 데이터 볼줄 아는데, 데이터 팀은 어려움. → 현업에서 데이터 소유권 분쟁이 일어남.
데이터를 주지 않는 것이 가장 큰 문제!! → 빌어야 준다
회사에서 할 수가 없다. → 직접해서 만들어서 보여줘라 → 아무도 안믿는건 미국도 똑같다. → 엑스트라 시간 쪼개서 보여줘라 → 데이터 팀이 없었다. → 데이터팀을 만들어서 팀장 되기도 한다
→ 하이브리드 조직이 되기 위해서 데이터팀을 운영해야 한다!!!
→ 데이터 타이틀 갖고 있는 사람들이 많지도 않고, 비싸다. → 투자 안하게 된다.
→ 아이덴티티가 매우 모호하다!! → 고도화되면서 갈라질 예정
리딩 : 위에서할지 모두가 할지 → GE 망했다. → 왜 하는지 모르곘다는 느낌이 많다. → 엔진 회사가 DT 하는 것이 어렵다. → 데이터 중심의 기업 문화

시애틀에 있다. 데이터 기반을 이 브런치에서 공유했다.

온프로미스 하둡 등을 깔았다. → 2014년 되어서야 실리콘 밸리에서 깔았다.
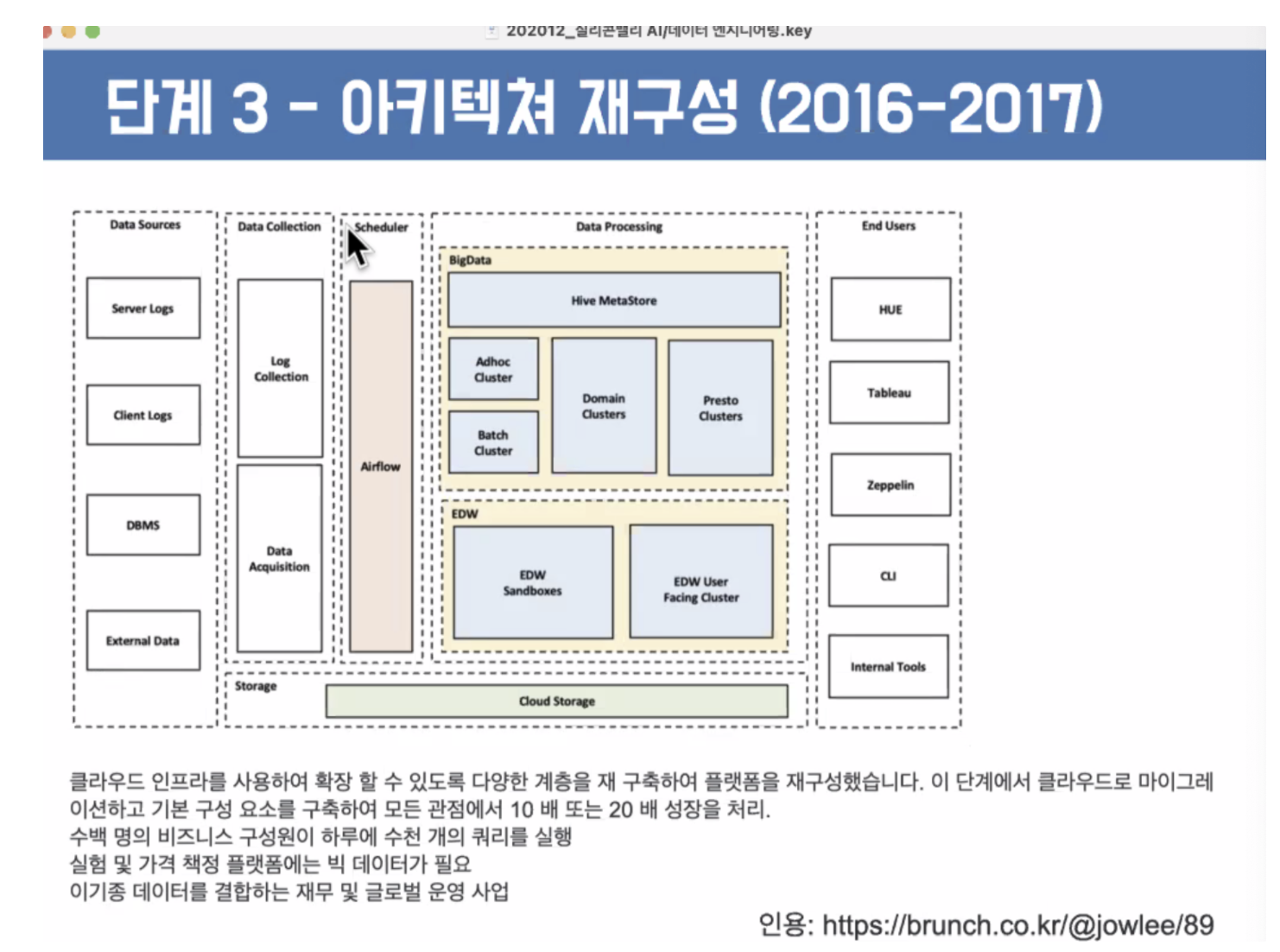
데이터를 실시간으로 뽑을 수 있도록 만들어 냈다. Likedin 도 데이터 인프라가 잘 만들어져서 문제가 없어졌다.
→ 첨언을 하자면, 구성을 하게 됬다. AWS에 환경을 만들어서 구성하게 됬다.
→ 마케팅하는 사람들이 수천건의 쿼리를 날릴수 있다. → 가격등도 테스팅 계속 하고 있다! ← 매우 흥미롭다. → 가격 트랙킹하는 툴도 있다. → 실험하는 환경
이기종 데이터도 결합함
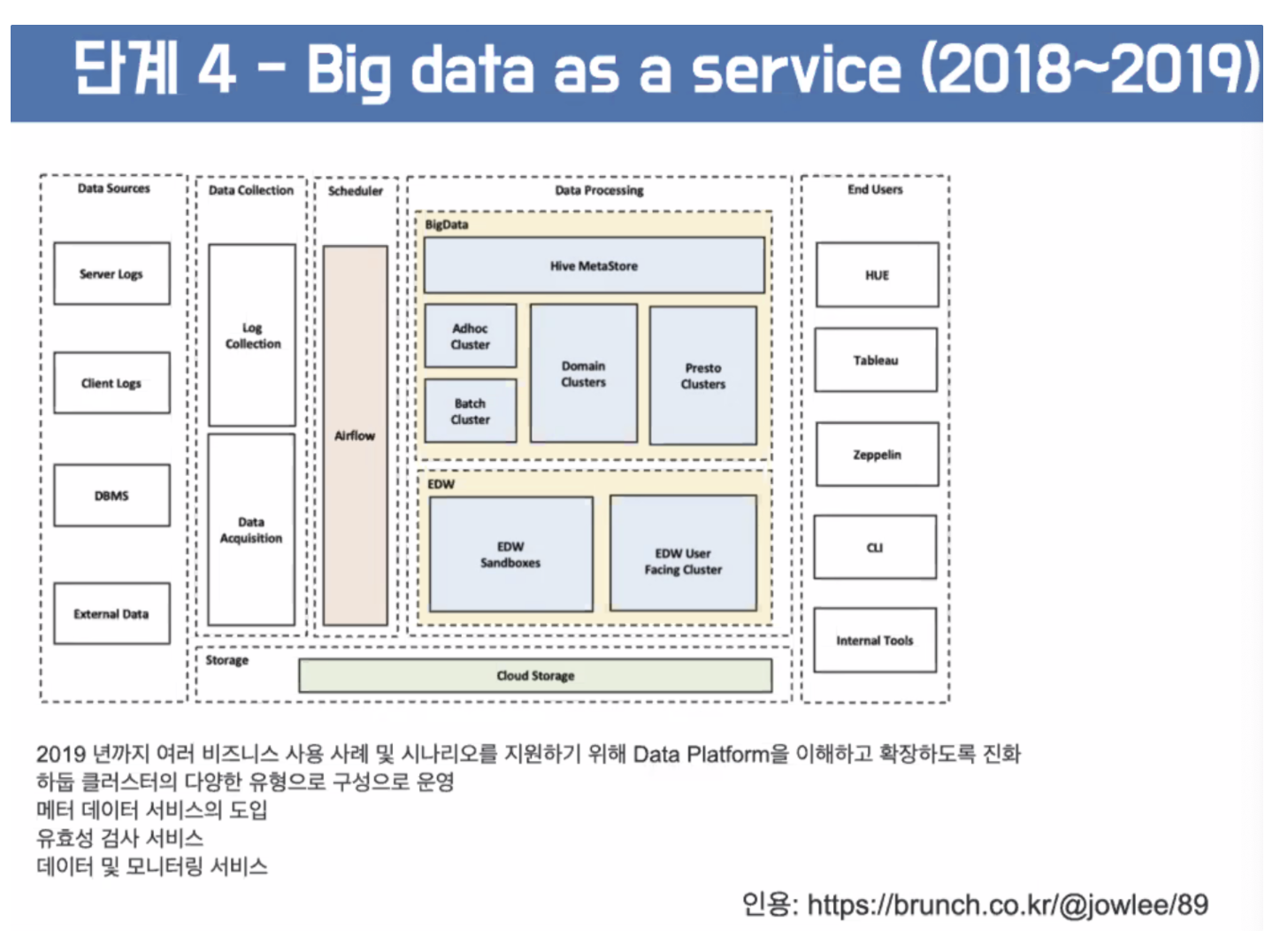
데이터 자체가 돈이다!! → 농약을 치면 땅은 나쁘지만 돈은 번다 → 데이터도 비슷하다.
→ 메타 데이터 서비스등을 통해서 관리와 운용을 해갔다. → 적재 적소에 서비스되도록 만들었다. → 쿠팡은 데이터 엔지니어링의 끝판왕에 와있다. → 데이터 클렌징 → 끝단에 와있다.
Linked in

2만명, 데이터 엔제니어, 사이언티스트, 애널리스트 매우 규모 크다
하둡도 운영 , azure로 옮기는 중 → 데이터 사이즈가 크다 → 친구추천, 잡 추천, 트렌드
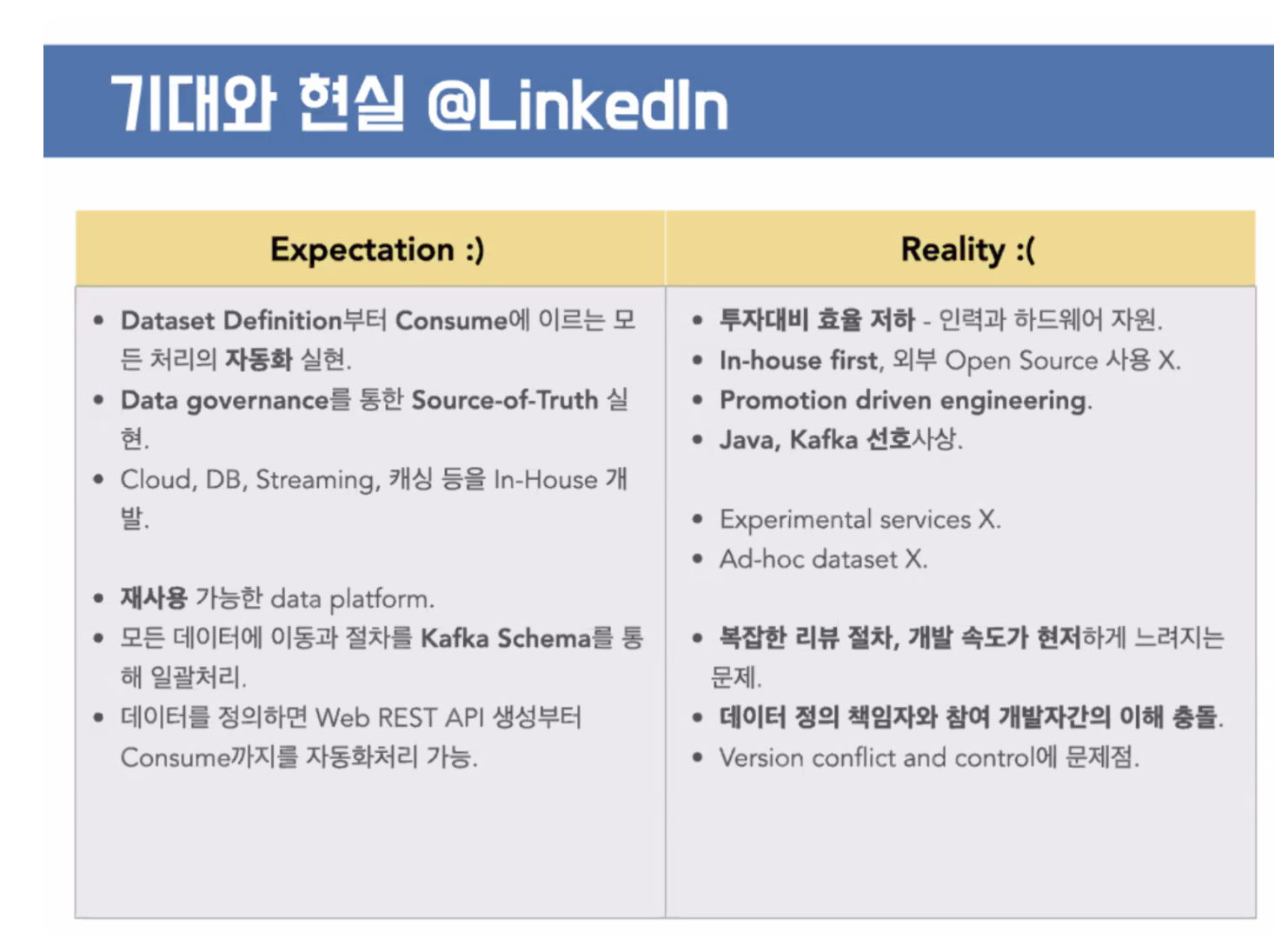
마른 걸레에서 물이 안나오는 경우가 있다. 장점 단점 등이 있다. → 데이터 셋을 만들면 정의만 하면, 자동화가 되어 있다. 너무 잘되있다.
→ 1개가 표준 → 1만 오천개의 기준이 있다.
cloud, db, 등 만들고, 카프카도 만들고 오픈소스 회사이다. →나쁜점도 있다. → 플랫폼있으면 재사용한다.
그렇다보니,,,, 투자를 많이해서 재사용 안하고, 엉켜있고 너무 쉽게 된다. → 빠르게 달릴 수가 없다.
이러한 싸움이 지속된다.
내부의 소스만을 써야한다. / 밖에 뭐가 좋은지를 모른다.
→ 회사가 순식간에 커보니까 문제가 생겼다. → 데이터 리뷰를 하는게 3개월이 걸린다.

데이터를 slice dice 해서 줄인다 → 거의 메가 바이트 수준으로 줄인다. !! 1번 날짜별로 줄이고, 날짜/사람/시간대별로 쪼개고 → 몇건인지가 중요하다

자동화, 일반적인 엔지니어 기반으로 api 만들고, 마이크로 서비스 만드록, 데이터 플로우 만들고,

실시간 처리, 배치, 클라우드 접근, 자동화
버튼등을 왼쪽에 둘지 오른쪽에 둘지를 보고 트래픽등을 보고 조회수를 높이도록 한다. → 고객 반응에 기반하여 제품을 만든다.
조금씩 올리는 Ramp up 기능이 있다.
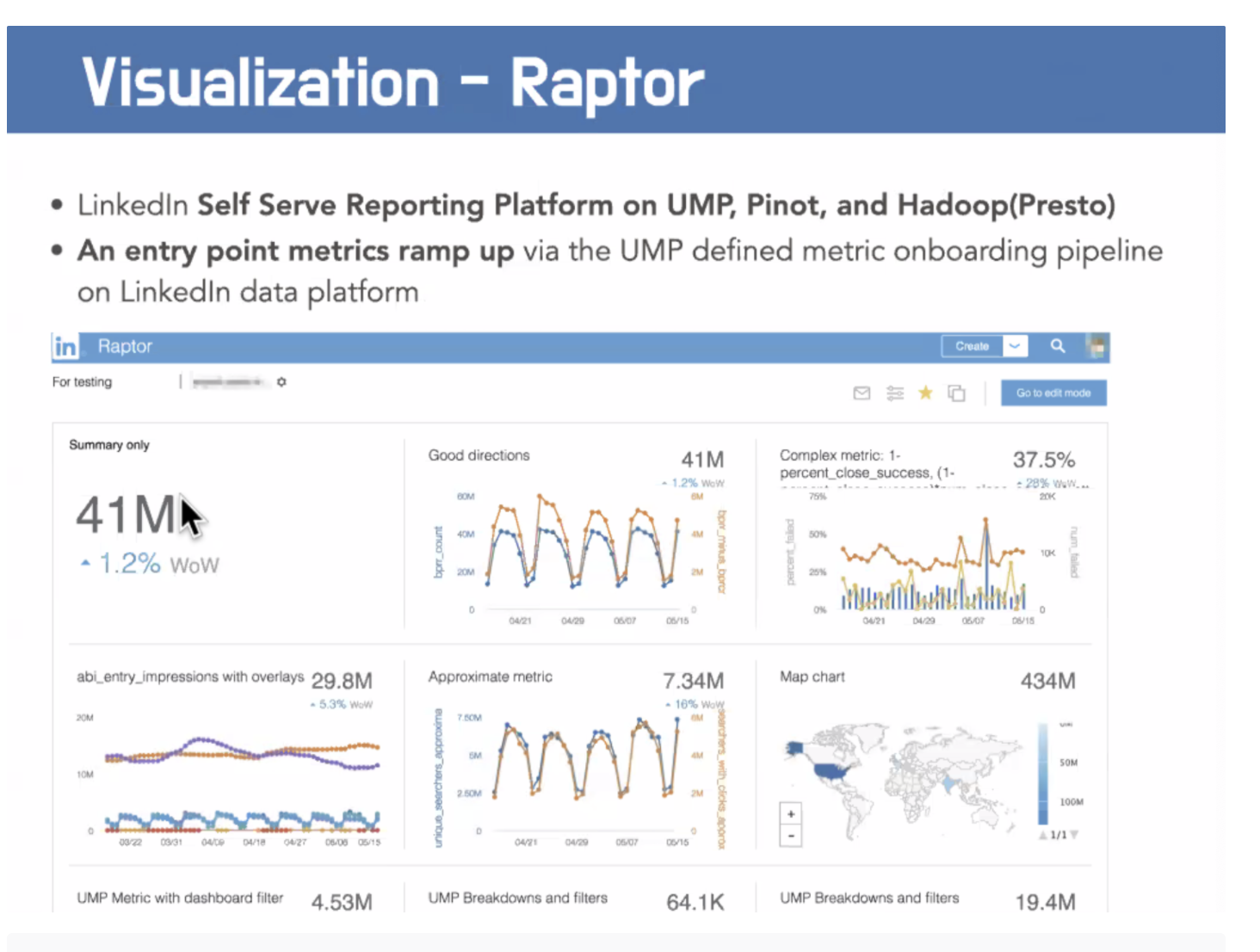
Data driven business by metrics
데이터가 많은데, 누가 오너십이 있다는 것을 확인할 수가 있다. 데이터에 태깅이 있으니 데이터가 언제 없어져야하는지를 볼수가 있다.

생각보다 옛날 트렌드만 보고 있는 경향이 강하다.
악마의 기업,
데이터 잘 활용하고 있기는 하다 → 데이터 트렌드 읽어서 경쟁사보다 싸게 해서 시장 지배한다.

고객 늘리게 커미션 준다. → 사이트 오른쪽에 광고 올리면 클릭하면 커미션 준다. → 엄청나게 준다. → 넥스텍 커미션으로 돈번다.
→ 크레딧카드, 등등 커미션 상당하다. EBATES이 전문적으로 해준다. ← 라쿠텐이 1조에 샀다. ← 4조를 벌었다...ㅎㅎ
광고 쉐어 상당하다.... 데이터만이 아니라 새로운 비즈니스 모델이 필요하다.

산타 알려주는 거 커스토머 서비스 등등 천천히 일어나고 있다.


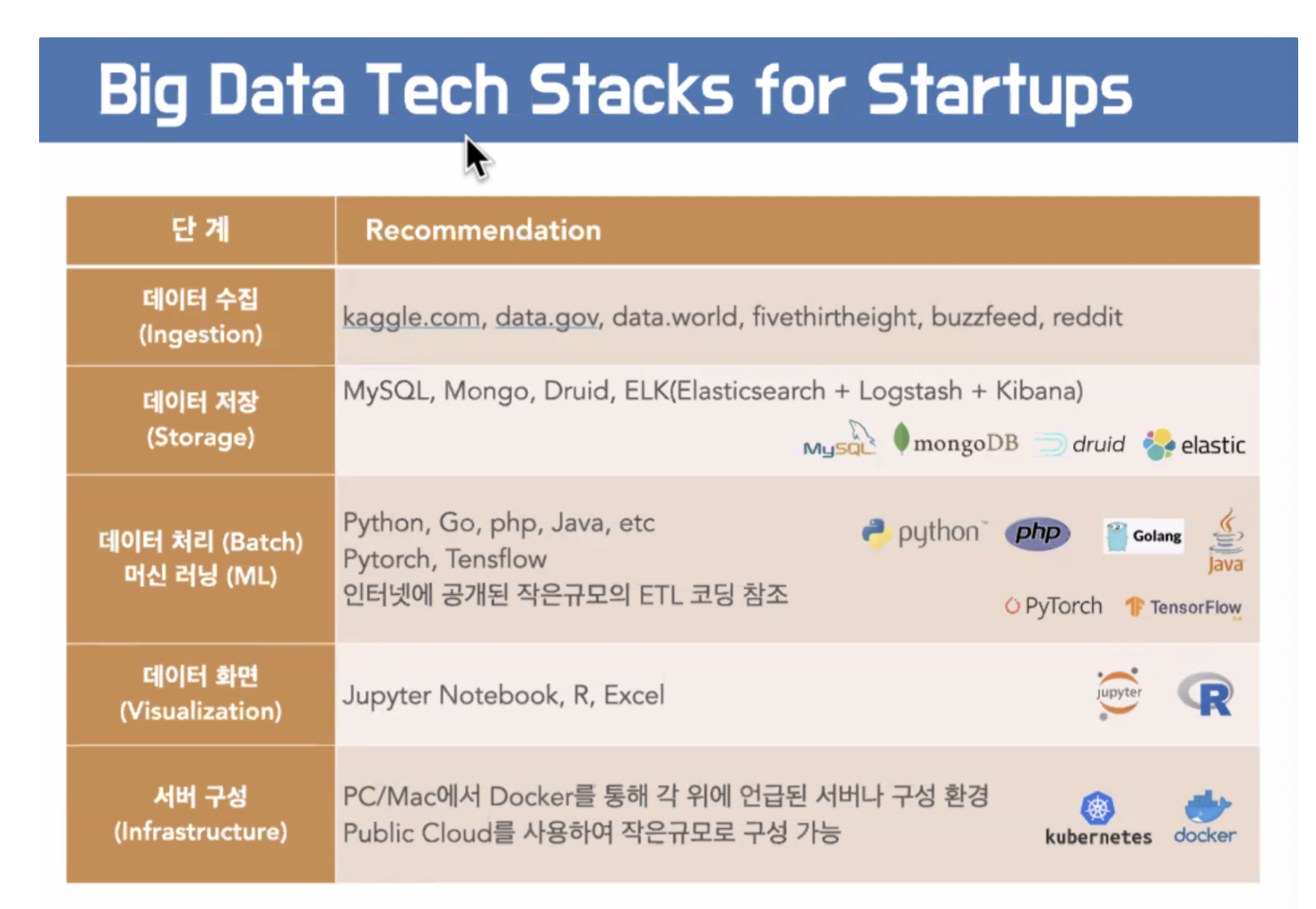
캐글에 데이터 엄청나게 많다. / 데이터 저장소 간단하게 저장하고 / 간단한 언어쓰고 / 데이터 화면 엑셀 써보고 운영하자
어제 내용 복습과 연계까지 해주시면서 쌀농사와 같은 찰떡같은 비유로 데이터 산업에 대해 명확한 이해를 시켜주신 강의 정말 감사드립니다. 이런 기회를 과기정통부에서 예산 더욱 많이 할당해주셔서 더 많은 기회를 얻기를 기도합니다.
대부분의 강연들은 무엇을 배우면 된다. 뭐가 필요하다. 업계에서는 이게 쓰인다. 정도인데 전체 프로세스와 시스템을 알려주셔서 업계에 대해서 이해가 되어서 정말 감사드립니다.
쿠팡 브런치 글 읽어보긴 했는데, 예전에 볼때는 이해가 안됬는데 앤드류박님 설명들으니 이제야 이해가 가네요..ㅎㅎㅎ 링크드인 예시까지 너무 감사합니당 ㅎㅎㅎ
이제 제가 아는 앤드류는 앤드류 앙, 앤드류 양 그리고 앤드류 박 님까지 모두 대가이신 분들 밖에 없네요. 제 영어 이름은 앤드류로 지어야 대가가 되지 않을까 싶네요 ㅎㅎㅎㅎ
앤드류 박님의 강의에 기반하여 질문드리자면, 일반적으로 취업에 관해 경험에 물어보면 개념적으로 하자면, 캐글을 해라, 데이터를 실제로 해봐라, 작은 회사에 가보라라고 하시지만, 하나의 토이 프로젝트/ 프로젝트를 하나하나 수행해나가서 못해도 5개 이상의 프로젝트를 담은 포트폴리오를 기반으로 회사를 지원하고자 합니다. 이를 위해서 말씀하신 "Big Data hierchy of Needs"에 기반한 구성요소 면목들을 적용하고자 하는데, 채용담당관 경험에서 비춰보셨을때, 어떤 것들을 중점적으로 보여주는 것이 경력을 보여주는 것이 좋을 까요....ㅎㅎㅎ
질의 응답
한국에서는 AI관련 업체로 들어가려면 AI관련경력이 있어야된다고 하던데...현재는 제조업분야 C#기반 Application을 개발하는 프리랜서로 하고 있습니다. 어떻게 하면 될까요?
미리 하고 있는게 맞다고 생각이 든다.
데이터 활용의 진화에 대해 더욱 깊게 알게된 것같습니다. 인상깊게 실리콘벨리의 사례 소개 감사합니다. 데이터 마이닝 기술도 중요해보이는데 관련 추가적으로 소개 가능하신가요?
데이터 엔지니어링은 마이닝을 벗어나지 않는다. → 이름이 바뀐 것이다. / 쿼리를 삼성 스킬로 썼는데 매우 좋게 쓴다. → 데이터 마이닝이 매우 중요하다
앤드류 박님의 강의에 기반하여 질문드리자면, 일반적으로 취업에 관해 경험에 물어보면 개념적으로 하자면, 캐글을 해라, 데이터를 실제로 해봐라, 작은 회사에 가보라라고 하시지만, 하나의 토이 프로젝트/ 프로젝트를 하나하나 수행해나가서 못해도 5개 이상의 프로젝트를 담은 포트폴리오를 기반으로 회사를 지원하고자 합니다. 이를 위해서 말씀하신 "Big Data hierchy of Needs"에 기반한 구성요소 면목들을 적용하고자 하는데, 채용담당관 경험에서 비춰보셨을때, 어떤 것들을 중점적으로 보여주는 것이 경력을 보여주는 것이 좋을 까요....ㅎㅎㅎ
인턴한테 바라는 게 다르고, 일반사람한테 보는 게 다른데 뽑는 사람을 뽑는 게 리스키하다. → 똑같은 고민을 한다. → 정 안되면 좋은 대학 뽑는다.....ㅠㅠ → 똑같이 하지 않은 것! → 예를 들면, 포트폴리오를 만들어 간다. (다 정리해서 간다. 남들과는 다르게,)
그냥 해서는 안되고, 인턴을 통해서 이력서에 한 줄, 커리어로 쓸려고 하면 안된다.
→ 자격증을 딸려고 한다. → 자격증 / 복수전공 / 학점 스타트업 / 코딩 → 후자 win
→ 실제 에너제틱하고 해본 사람을 원한다. → 가기 위해서 스펙을 만들기 보다는 → 가서 할 일을 지금 하고 있어라. → 토이 프로젝트도 하고
→ 목소리 변조 , 사람 얼굴 인식 → 깃허브로 제대로 만들어 놓자!! → 커밋을 오지게 해서 → highlight을 보게 한다. → 리듬에 맞게 올리자!! → 경험이 없어도 뽑힐 수가 있고 뽑게 된다.
규제의 관점에서 설명가능한 ai의 문제가 이슈가 되고 있는데, tensflow 예에서 말씀주신것 처럼 기술적으로 구지 블락박스처럼 되지 않고도 이런것이 가능한것인지, 그리고 링킨에서 데이터마다 태그인을 붙여 책임자를 알수있다고 하셨는데 좀 더 설명해 주실수 있으신지요? 오늘 강연 유익하게 잘 들었습니다.감사합니다
→ 유럽 법떄문에 그렇다
포트폴리오 ? → 이메일로 보내놓고, 한 개정도 들고가도 한다. → 그렇게 하면 좋다!!
'Identity_Developer&Analyst > 02_Data Analyst' 카테고리의 다른 글
| 데이터 분석가로 가는 길 : 논문 (0) | 2020.12.20 |
|---|---|
| [201209] Kosen Online Open Seminar (0) | 2020.12.18 |
| 데이터 사이언스 특강(Data-teller 데이터 속 이야기) (0) | 2020.12.18 |
| 11월 16일 삼정 KPMG 데이터 사이언티스트 특강 (0) | 2020.12.18 |



